TIL: Vision-Language Models Read Worse (or Better) Than You Think
Welcome to this new TIL, introducing ReadBench. ReadBench is a very straightforward benchmark that we developed to evaluate an important-but-understated aspect of multimodal AI: the ability of models to actually read, reason about and extract information from images of text.

TIL
Current Vision-Language Models (VLMs) are very cool, very promising, and do increasingly well on a wide variety of benchmarks. Quite rightfully, the vast majority of these benchmarks focus on their visual understanding: they’re vision models, after all.
The improvement of VLMs has, in turn, led to state-of-the-art multimodal retrieval methods such as ColPali or DSE. These methods have themselves paved the way for the advent of fully Visual RAG, where images of documents are retrieved then directly passed to a VLM, without any text-to-image extraction step.
There is one thing that is pretty important for this approach that most benchmarks don’t currently test: how well can VLMs actually read text? Many documents are, after all, 95% text (trust me).
We were curious about this, so we built ReadBench to evaluate this. ReadBench is a very straightforward benchmark: it takes a few common textual benchmarks, for both short and long context inputs, converts the contexts to images while keeping the questions as text, and then evaluates how the model performance varies between text and multimodal inputs. This setup is similar to a usual Visual RAG pipeline.
The results? Almost all VLMs experience some degree of performance degradation on all multimodal settings, although it is much less pronounced on short, sub-1-page inputs, and some fare noticeably better (I apologise for previously disrespecting GPT-4o).
On longer inputs, all models experience very significant performance degradation, meaning that passing multiple pages to your Visual RAG pipeline is not yet a viable solution.
These findings match the concurrent-and-somewhat-different study by the MixedBread team: While multimodal Retrieval is state-of-the-art, Generation based on multimodal inputs is not, although it’s progressing rapidly.
ReadBench is released publicly, with the data on HuggingFace (you’ll need to fetch GPQA yourself), the code on GitHub, and more formal details on arXiv. All you need to do to score a new model is simply add a single method to get its predictions, and you’re good to go :).
ReadBench In Slightly More Details
Constructing the Benchmark
To construct ReadBench, we went with a simple approach: pick a few popular benchmarks, which are text-only, and convert them to screenshots of text. To accurately represent real-world visual RAG use cases, we went with a truly multimodal scenario rather than fully image-based:
- All instructions and questions are kept as text.
- All context (for context-based QA) and answer options (for multiple-choice benchmarks without context) are converted to images.
As for the datasets, we picked a handful of very popular benchmarks. For short-context, we use:
- MMLU-Redux: An updated version of MMLU, which improves the overall quality of the dataset by filtering ambiguous or flat-out wrong questions.
- MMLU-Pro: A harder version of MMLU with a specific focus on STEM, where each question has 10 answer options rather than just 4.
- GPQA-Diamond: A very hard “graduate-level” science multiple-choice questions benchmark, where answering correctly requires very advanced knowledge of scientific topics.
For longer context, we used:
- BABILong and all 10 of its component questions. Babilong Q1 is a “Needle-in-a-Haystack” benchmark, where all the model has to do is retrieve a single fact clearly stated somewhere in the context. All other 9 questions add various layers of simple reasoning to the haystack, such as counting, linking two facts together, etc.
- Four QA subsets of LongBench, to provide a variety of evaluation topics
With these datasets chosen, we then ran them through a simple pipeline which generated screenshots of the text, selecting a 92.9 PPI ratio over the standardized A4 page size. We chose 92.9 as it’s very close to the 93 PPI standard of “most scanners” and produces a neat 768 pixel width.
Finally, we ran some experiments, and found that by downsampling each individual dataset to 35 examples per subset was a sweet spot where all model scores were very highly correlated with running the full dataset while greatly reducing the time and compute/money needed to run the benchmark.
High-Resolution Once Again Doesn’t Matter For Generation
Before running the full benchmark, one thing we were curious about was the perennial question: Does Resolution Matter? What I’d consider the authoritative resource on the subject, Lucas Beyer’s blog post on ViTs, seems to indicate that it doesn’t really: even if your image looks blurry to humans, as long as it’s readable enough, model performance shouldn’t be strongly affected, if at all.
In the figure below, we decided to try out a range of PPIs on an A4 page size: from 72ppi, a common “lowish” ppi ratio, where a full A4 page is 595 x 841 pixels and looks pretty blurry to a human reader, to 300ppi, the famous “retina” PPI ratio, where an A4 page is 2481 x 3507 and looks crystal clear.
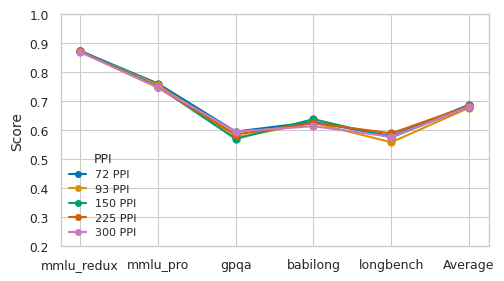
It turns out that resolution, for current VLMs, indeed matters very little: Gemini 2.0 Flash performs more or less exactly the same at 72 PPI as it does at 300 PPI. This is an interesting finding, as it confirms a lot of what we know about “vision” models, but is not aligned with recent results in multimodal retrieval, which seemed to imply that higher resolutions lead to better retrieval quality (although, the model used in this study being a late interaction model, it might be because it allows for more fine-grained scoring due to how MaxSim works).
So, how well can they read?
Below, you’ll find the table showing how each model performed on each individual benchmark, as well as aggregated metrics based on page count (page count, in multimodal world, being a proxy for context length).
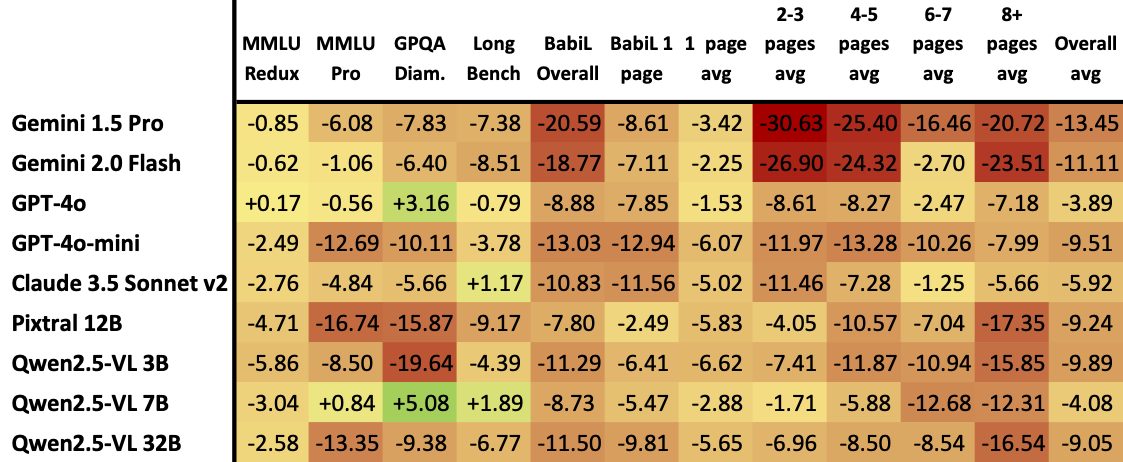
Full interpretation is left to the readers (and the arXiv preprint!), but there are a few clear signals:
- Performance degradation on short context seems to be somewhat correlated with task difficulty. MMLU-Redux is easier than MMLU-Pro which is easier than GPQA-Diamond, and we can see that models seem to be pretty decent across the board at extracting easy answers from images, but less so when things get tougher and require more reasoning.
- Overall, on short context, most models do OK though they experience some degradation, even on the harder tasks.
- Longer context inputs trigger much more noticeable degradation, to the point where you might have second thoughts about passing multiple pages to your Visual RAG pipeline. This is consistent with anecdotal reports and other people’s results.
- GPT-4o is exceptionally good, and experiences relatively little degradation across the board, being a clear outlier (along with one of the Qwen2.5-VLs, though its absolute performance is obviously much worse, thus less notable). Interestingly, it seems that it gets better performance on GPQA with multimodal inputs, which is surprising at first, but also matches with analysis of how GPT-4o evolved over time: as it got better at multimodal reasoning and programming, it has been reported that its GPQA performance sharply dropped. It might not be that multimodal 4o is amazing at GPQA, but rather that text 4o has, for unknown reasons, very degraded performance on it.
No “Universal Trigger”: All Models Have Independent Failure Cases
Finally, we looked at the degradation overlap between models, and measured the Jaccard Similarity between the sets of performance mismatches across models. Phew, that’s a mouthful, but it’s actually very simple. It’s a fancy way of saying: what is the percentage of questions triggering a mismatch between text and multimodal inputs in Model X that also trigger a mismatch in Model Y?
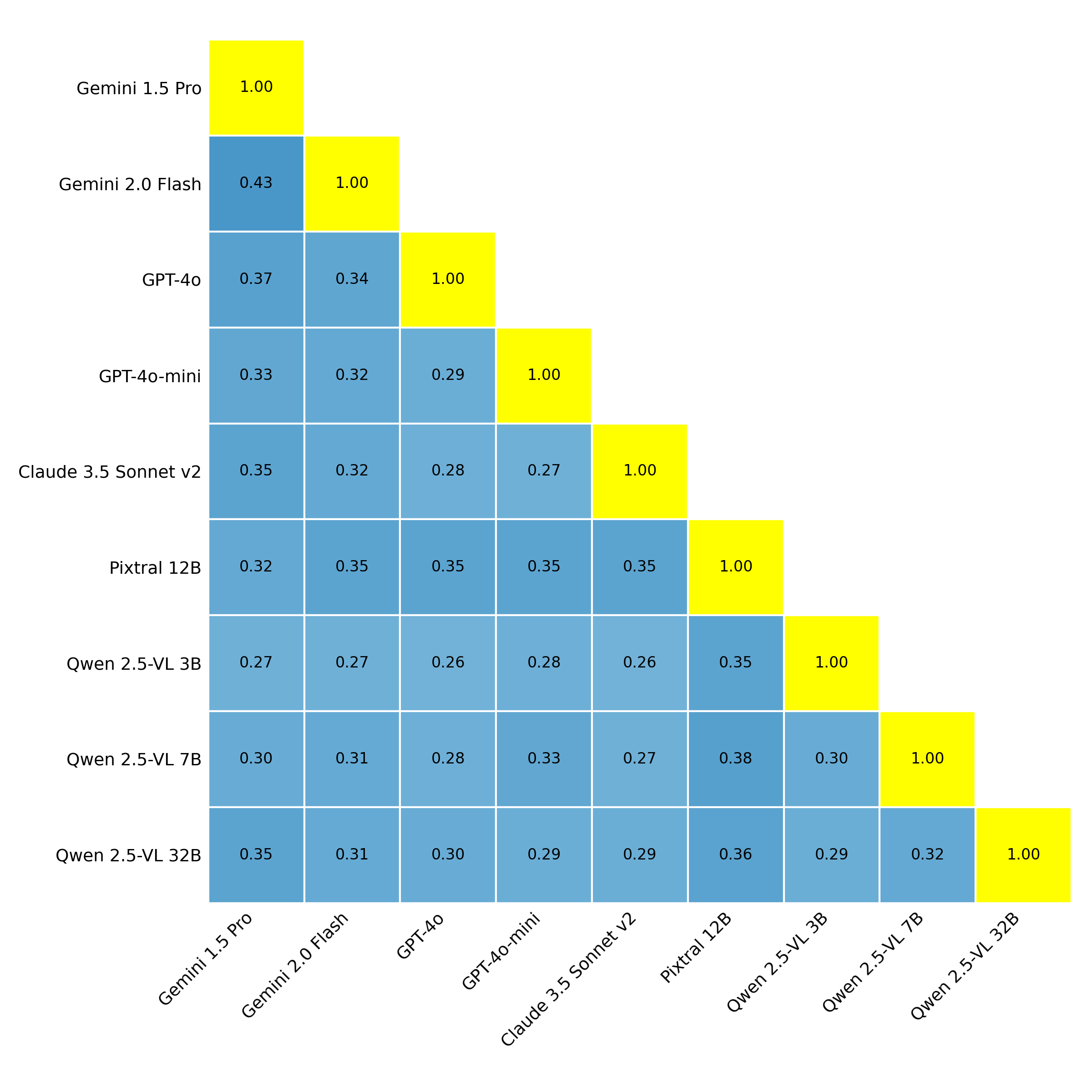
And what this shows us is that there seems to actually be relatively little overlap. Interestingly, models of the same family (the 4os, the Geminis, and the Qwen2.5-VLs) don’t seem to have significantly more overlap between themselves, despite most likely having been trained on very similar data.
We were also curious about the mismatch distribution, that is, how many questions cause degradations in a certain number of models?:
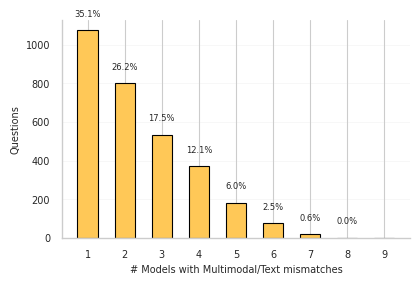
An interesting finding here, which admittedly somewhat surprised me, is that no single input appears to be a “universal trigger” for failure. The most models any given question has tripped up is 7, out of 9 evaluated, and even this is a very small set of questions: just 0.6%! Inversely, over a third of questions trigger a mismatch for just one model, and another 26% do so in just two models!
In practice, what this shows is that the performance degradations we have observed seem to be caused by a variety of reasons, and are very model-specific – there doesn’t seem to be a one-size-fits-all way of messing up with their reading.
What now?
While ReadBench provides a clear snapshot of current limitations, there are exciting opportunities ahead:
- Extending evaluations to multilingual contexts.
- Incorporating additional modalities like audio and video.
- Exploring deeper, more nuanced dataset designs for future benchmarking.