# Finally, a Replacement for BERT: Introducing ModernBERT
Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar
Hallström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal
Ladhak, Tom Aarsen, Nathan Cooper, Griffin Adams, Johno Whitaker, Jeremy
Howard, Iacopo Poli
2024-12-19
- [Finally, a Replacement for BERT](#finally-a-replacement-for-bert)
- [TL;DR](#tldr)
- [Introduction](#introduction)
- [Decoder-only models](#decoder-only-models)
- [Encoder-only models](#encoder-only-models)
- [Performance](#performance)
- [Overview](#overview)
- [Efficiency](#efficiency)
- [Why is ModernBERT, well, Modern?](#why-is-modernbert-well-modern)
- [Meet the New Transformer, Same as the Old
Transformer](#meet-the-new-transformer-same-as-the-old-transformer)
- [Upgrading a Honda Civic for the Race
Track](#upgrading-a-honda-civic-for-the-race-track)
- [Training](#training)
- [Conclusion](#conclusion)
- [Links](#links)
# Finally, a Replacement for BERT
> **Note**
>
> This is a cross-post of the [announcement blog post posted on the 🤗
> HuggingFace blog](https://huggingface.co/blog/modernbert).
## TL;DR
This blog post introduces
[ModernBERT](https://huggingface.co/collections/answerdotai/modernbert-67627ad707a4acbf33c41deb),
a family of state-of-the-art encoder-only models representing
improvements over older generation encoders across the board, with a
**8192** sequence length, better downstream performance and much faster
processing.
ModernBERT is available as a *slot-in* replacement for any BERT-like
models, with both a **base** (149M params) and **large** (395M params)
model size.
Click to see how to use these models with transformers
ModernBERT will be included in v4.48.0 of `transformers`. Until then, it
requires installing transformers from main:
``` sh
pip install git+https://github.com/huggingface/transformers.git
```
Since ModernBERT is a Masked Language Model (MLM), you can use the
`fill-mask` pipeline or load it via `AutoModelForMaskedLM`. To use
ModernBERT for downstream tasks like classification, retrieval, or QA,
fine-tune it following standard BERT fine-tuning recipes. **⚠️ If your
GPU supports it, we recommend using ModernBERT with Flash Attention 2 to
reach the highest efficiency. To do so, install Flash Attention as
follows, then use the model as normal:**
``` bash
pip install flash-attn
```
Using `AutoModelForMaskedLM`:
``` python
from transformers import AutoTokenizer, AutoModelForMaskedLM
model_id = "answerdotai/ModernBERT-base"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForMaskedLM.from_pretrained(model_id)
text = "The capital of France is [MASK]."
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
# To get predictions for the mask:
masked_index = inputs["input_ids"][0].tolist().index(tokenizer.mask_token_id)
predicted_token_id = outputs.logits[0, masked_index].argmax(axis=-1)
predicted_token = tokenizer.decode(predicted_token_id)
print("Predicted token:", predicted_token)
# Predicted token: Paris
```
Using a pipeline:
``` python
import torch
from transformers import pipeline
from pprint import pprint
pipe = pipeline(
"fill-mask",
model="answerdotai/ModernBERT-base",
torch_dtype=torch.bfloat16,
)
input_text = "He walked to the [MASK]."
results = pipe(input_text)
pprint(results)
```
**Note:** ModernBERT does not use token type IDs, unlike some earlier
BERT models. Most downstream usage is identical to standard BERT models
on the Hugging Face Hub, except you can omit the `token_type_ids`
parameter.
## Introduction
[BERT](https://huggingface.co/papers/1810.04805) was released in 2018
(millennia ago in AI-years!) and yet it’s still widely used today: in
fact, it’s currently the second most downloaded model on the
[HuggingFace hub](https://huggingface.co/models?sort=downloads), with
more than 68 million monthly downloads, only second to [another encoder
model fine-tuned for
retrieval](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2).
That’s because its *encoder-only architecture* makes it ideal for the
kinds of real-world problems that come up every day, like retrieval
(such as for RAG), classification (such as content moderation), and
entity extraction (such as for privacy and regulatory compliance).
Finally, 6 years later, we have a replacement! Today, we at
[Answer.AI](http://Answer.AI) and [LightOn](https://www.lighton.ai/)
(and friends!) are releasing ModernBERT. ModernBERT is a new model
series that is a Pareto improvement over BERT and its younger siblings
across both **speed** and **accuracy**. This model takes dozens of
advances from recent years of work on large language models (LLMs), and
applies them to a BERT-style model, including updates to the
architecture and the training process.
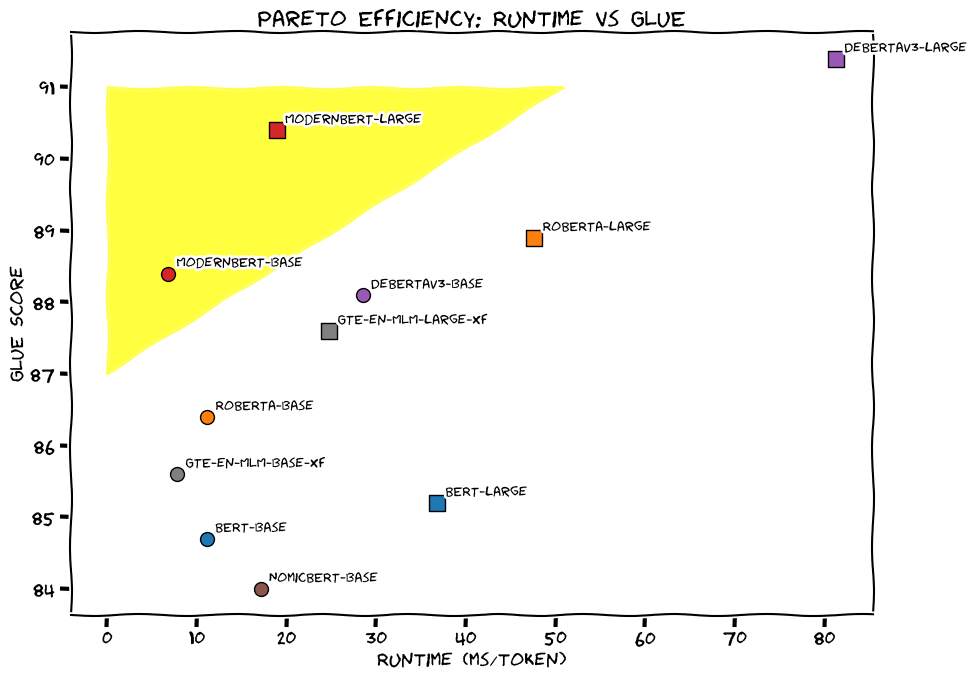
We expect to see ModernBERT become the new standard in the numerous
applications where encoder-only models are now deployed, such as in RAG
pipelines (Retrieval Augmented Generation) and recommendation systems.
In addition to being faster and more accurate, ModernBERT also increases
context length to 8k tokens (compared to just 512 for most encoders),
and is the first encoder-only model that includes a large amount of code
in its training data. These features open up new application areas that
were previously inaccessible through open models, such as large-scale
code search, new IDE features, and new types of retrieval pipelines
based on full document retrieval rather than small chunks.
But in order to explain just what we did, let’s first take a step back
and look at where we’ve come from.
## Decoder-only models
The recent high-profile advances in LLMs have been in models like
[GPT](https://huggingface.co/openai-community/openai-gpt),
[Llama](https://huggingface.co/meta-llama), and
[Claude](https://www.anthropic.com/claude). These are *decoder-only
models,* or generative models. Their ability to generate human-like
content has enabled astonishing new GenAI application areas like
generated art and interactive chat. These striking applications have
attracted major investment, funded booming research, and led to rapid
technical advances. What we’ve done, essentially, is port these advances
back to an encoder-only model.
Why? Because many practical applications need a model that’s **lean**
and **mean**! And it doesn’t need to be a generative model.
More bluntly, decoder-only models are *too big*, *slow*, ***private***,
and *expensive* for many jobs. Consider that the original
[GPT-1](https://huggingface.co/openai-community/openai-gpt) was a 117
million parameter model. The [Llama
3.1](https://huggingface.co/meta-llama/Llama-3.1-405B) model, by
contrast, has 405 *billion* parameters, and its technical report
describes a data synthesis and curation recipe that is too complex and
expensive for most corporations to reproduce. So to use such a model,
like ChatGPT, you pay in cents and wait in seconds to get an API reply
back from heavyweight servers outside of your control.
Of course, the open-ended capabilities of these giant generative models
mean that you can, in a pinch, press them into service for
non-generative or *discriminative* tasks, such as classification. This
is because you can describe a classification task in plain English and …
just ask the model to classify. But while this workflow is great for
prototyping, you don’t want to pay prototype prices once you’re in mass
production.
The popular buzz around GenAI has obscured the role of *encoder-only
models*. These are the workhorses of practical language processing, the
models that are actually being used for such workloads right now in many
scientific and commercial applications.
## Encoder-only models
The output of an encoder-only model is a list of numerical values (an
*embedding vector*). You might say that instead of answering with text,
an encoder model literally *encodes* its “answer” into this compressed,
numerical form. That vector is a compressed representation of the
model’s input, which is why encoder-only models are sometimes referred
to as *representational models*.
While decoder-only models (like a GPT) can do the work of an
encoder-only model (like a BERT), they are hamstrung by a key
constraint: since they are *generative models*, they are mathematically
“not allowed” to “peek” at later tokens. They can only ever *look
backwards*. This is in contrast to encoder-only models, which are
**trained so each token can look forwards *and* backwards
(bi-directionally)**. They are built for this, and it makes them very
efficient at what they do.
Basically, a frontier model like OpenAI’s O1 is like a Ferrari SF-23.
It’s an obvious triumph of engineering, designed to win races, and
that’s why we talk about it. But it takes a special pit crew just to
change the tires and you can’t buy one for yourself. In contrast, a BERT
model is like a Honda Civic. It’s *also* an engineering triumph, but
more subtly, since *it* is engineered to be affordable, fuel-efficient,
reliable, and extremely useful. And that’s why they’re absolutely
everywhere.
You can see this by looking at it a number of ways.
***Supporting generative models***: One way to understand the prevalence
of representational models (encoder-only) is to note how frequently they
are used in concert with a decoder-only model to make a system which is
safe and efficient.
The obvious example is RAG. Instead of relying on the LLM’s knowledge
trained into the model’s parameters, the system uses a document store to
furnish the LLM with information relevant to the query. But of course
this only defers the problem. If the LLM doesn’t know which documents
are relevant to the query, then the system will need some other process
to select those documents? It’s going to need a model which is fast and
cheap enough that it can be used to encode the large quantities of
information needed to make the LLM useful. That model is often a
BERT-like encoder-only model. For more details on how Encoders like
ModernBERT are critical in RAG pipelines, see [this talk by Benjamin
Clavié](https://parlance-labs.com/education/rag/ben.html).
Another example is supervision architectures, where a cheap classifier
might be used to ensure that generated text does not violate content
safety requirements.
In short, whenever you see a decoder-only model in deployment, there’s a
reasonable chance an encoder-only model is also part of the system. But
the converse is not true.
***Encoder-based systems***: Before there was GPT, there were content
recommendations in social media and in platforms like Netflix. There was
ad targeting in those venues, in search, and elsewhere. There was
content classification for spam detection, abuse detection, etc.. These
systems were not built on generative models, but on representational
models like encoder-only models. And all these systems are still out
there and still running at enormous scale. Imagine how many ads are
targeted per second around the world!
***Downloads***: On HuggingFace,
[RoBERTa](https://huggingface.co/FacebookAI/roberta-base), one of the
leading BERT-based models, has more downloads than the 10 most popular
LLMs on HuggingFace combined. In fact, currently, encoder-only models
add up to over a billion downloads per month, nearly three times more
than decoder-only models with their 397 million monthly downloads. In
fact, the \`fill-mask\` model category, composed of encoder “base
models” such as ModernBERT, ready to be fine-tuned for other downstream
applications, is the most downloaded model category overall.
***Inference costs***: What the above suggests, is that on an
inference-per-inference basis, there are many times more inferences
performed per year on encoder-only models than on decoder-only or
generative models. An interesting example is
[FineWeb-Edu](https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1),
where model-based quality filtering had to be performed over 15 trillion
tokens. The FineWeb-Edu team chose to generate annotations with a
decoder-only model,
[Llama-3-70b-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct),
and perform the bulk of the filtering with [a fine-tuned BERT-based
model](https://huggingface.co/HuggingFaceFW/fineweb-edu-classifier).
This filtering took 6,000 H100 hours, which, at [HuggingFace Inference
Points](https://huggingface.co/pricing)’ pricing of $10/hour, comes to a
total of $60,000. On the other hand, feeding 15 trillion tokens to
popular decoder-only models, even with the lowest-cost option of using
[Google’s Gemini Flash and its low inference cost of $0.075/million
tokens](https://ai.google.dev/pricing#1_5flash), would cost over one
million dollars!
## Performance
### Overview
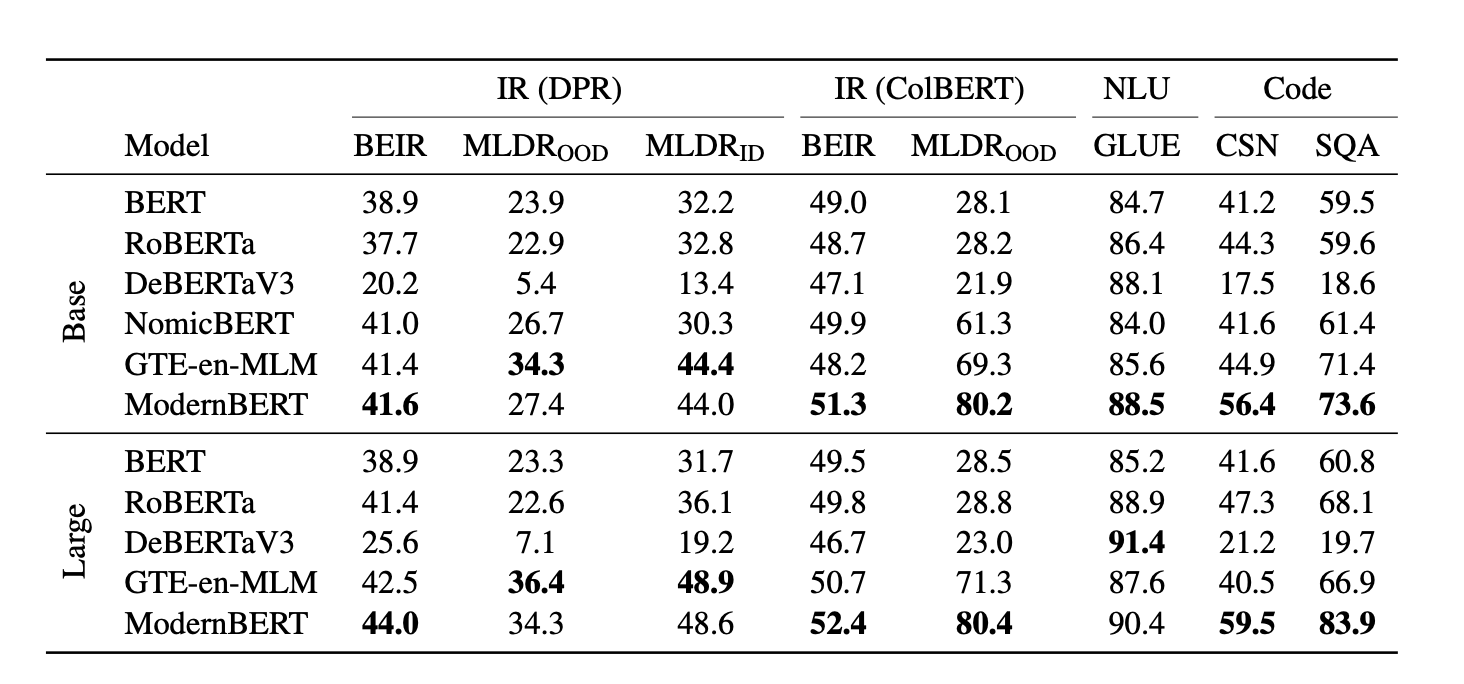
Here’s a snapshot of the accuracy of ModernBERT and other models across
a range of tasks, as measured by standard academic benchmarks – as you
can see, ModernBERT is the only model which is a **top scorer across
every category**, which makes it the one model you can use for all your
encoder-based tasks:
If you’ve ever done an NLP competition on
[Kaggle](https://www.kaggle.com/), then you’ll know that
[DeBERTaV3](https://huggingface.co/microsoft/deberta-v3-base) has been
the choice of champions for years. But no longer: not only is ModernBERT
the first base-size model to beat DeBERTaV3 on GLUE, it also uses less
than **1/5th** of Deberta’s memory.
And of course, ModernBERT is fast. It’s **twice** as fast as DeBERTa –
in fact, up to **4x** faster in the more common situation where inputs
are mixed length. Its long context inference is nearly **3 times**
faster than other high-quality models such as
[NomicBERT](https://huggingface.co/nomic-ai/nomic-bert-2048) and
[GTE-en-MLM](https://huggingface.co/Alibaba-NLP/gte-en-mlm-base).
ModernBERT’s context length of 8,192 tokens is over **16x** larger than
most existing encoders. This is critical, for instance, in RAG
pipelines, where a small context often makes chunks too small for
semantic understanding. ModernBERT is also the state-of-the-art long
context retriever with
[ColBERT](https://huggingface.co/colbert-ir/colbertv2.0), and is 9
percentage points above the other long context models. Even more
impressive: this very quickly trained model, simply tuned to compare to
other backbones, outperforms even widely-used retrieval models on
long-context tasks!
For code retrieval, ModernBERT is unique. There’s nothing to really
compare it to, since there’s never been an encoder model like this
trained on a large amount of code data before. For instance, on the
[StackOverflow-QA dataset
(SQA)](https://www.kaggle.com/datasets/imoore/60k-stack-overflow-questions-with-quality-rate),
which is a hybrid dataset mixing both code and natural language,
ModernBERT’s specialized code understanding and long-context
capabilities make it the only backbone to score over 80 on this task.
This means whole new applications are likely to be built on this
capability. For instance, imagine an AI-connected IDE which had an
entire enterprise codebase indexed with ModernBERT embeddings, providing
fast long context retrieval of the relevant code across all
repositories. Or a code chat service which described how an application
feature worked that integrated dozens of separate projects.
Compared to the mainstream models, ModernBERT performs better across
nearly all three broad task categories of retrieval, natural language
understanding, and code retrieval. Whilst it slightly lags
[DeBERTaV3](https://huggingface.co/microsoft/deberta-v3-base) in one
area (natural language understanding), it is many times faster. Please
note that ModernBERT, as any other base model, can only do masked word
prediction out-of-the-box. To be able to perform other tasks, the base
model should be fine-tuned as done in these
[boilerplates](https://github.com/AnswerDotAI/ModernBERT/tree/main/examples).
Compared to the specialized models, ModernBERT is comparable or superior
in most tasks. In addition, ModernBERT is faster than most models across
most tasks, and can handle inputs up to 8,192 tokens, 16x longer than
the mainstream models.
### Efficiency
Here’s the memory (max batch size, BS) and Inference (in thousands of
tokens per second) efficiency results on an NVIDIA RTX 4090 for
ModernBERT and other decoder models:
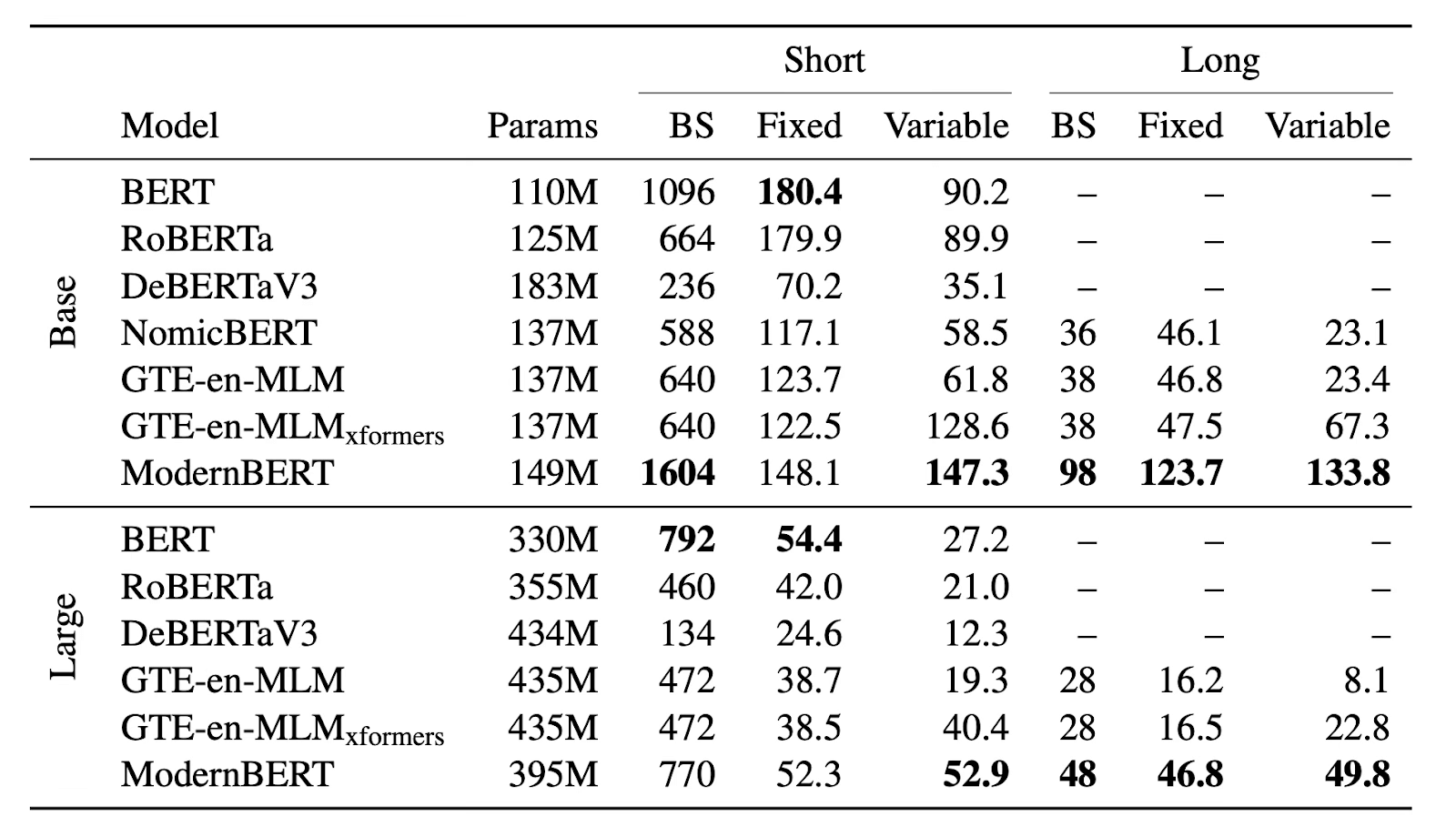
The first thing you might notice is that we’re analysing the efficiency
on an affordable consumer GPU, rather than the latest unobtainable hyped
hardware. **First and foremost, ModernBERT is focused on practicality,
not hype.**
As part of this focus, it also means we’ve made sure ModernBERT works
well for real-world applications, rather than just benchmarks. Models of
this kind are normally tested on just the one exact size they’re best at
– their maximum context length. That’s what the “fixed” column in the
table shows. But input sizes vary in the real world, so that’s the
performance we worked hard to optimise – the “variable” column. As you
can see, for variable length inputs, ModernBERT is much faster than all
other models.
For long context inputs, which we believe will be the basis for the most
valuable and important future applications, ModernBERT is **2-3x**
faster than the next fastest model. And, on the “practicality” dimension
again: ModernBERT doesn’t require the additional heavy
“[xformers](https://github.com/facebookresearch/xformers)” dependency,
but instead only requires the now commonplace [Flash
Attention](https://github.com/Dao-AILab/flash-attention) as a
dependency.
Furthermore, thanks to ModernBERT’s efficiency, it can use a larger
batch size than nearly any other model, and can be used effectively on
smaller and cheaper GPUs. The efficiency of the base size, in
particular, may enable new applications that run directly in browsers,
on phones, and so forth.
## Why is ModernBERT, well, Modern?
Now, we’ve made our case to why we **should** give some more love to
encoder models. As trusted, under-appreciated workhorses, they’ve had
surprisingly few updates since 2018’s BERT!
Even more surprising: since RoBERTa, there has been no encoder providing
overall improvements without tradeoffs (fancily known as “***Pareto
improvements***”): DeBERTaV3 had better GLUE and classification
performance, but sacrificed both efficiency and retrieval. Other models,
such as [AlBERT](https://huggingface.co/albert/albert-base-v2), or newer
ones, like GTE-en-MLM, all improved over the original BERT and RoBERTa
in some ways but regressed in others.
However, since the duo’s original release, we’ve learned an enormous
amount about how to build better language models. If you’ve used LLMs at
all, you’re very well aware of it: while they’re rare in the
encoder-world, *Pareto improvements* are constant in decoder-land, where
models constantly become better at everything. And as we’ve all learned
by now: model improvements are only partially magic, and mostly
engineering.
The goal of the (hopefully aptly named) ModernBERT project was thus
fairly simple: bring this modern engineering to encoder models. We did
so in three core ways:
1. a **modernized transformer architecture**
2. **particular attention to efficiency**
3. **modern data scales & sources**
### Meet the New Transformer, Same as the Old Transformer
The Transformer architecture has become dominant, and is used by the
vast majority of models nowadays. However, it’s important to remember
that there isn’t one but many *Transformers*. The main thing they share
in common is their deep belief that attention is indeed all you need,
and as such, build various improvements centered around the attention
mechanism.
ModernBERT takes huge inspiration from the Transformer++ (as coined by
[Mamba](https://arxiv.org/abs/2312.00752)), first used by the [Llama2
family of models](https://arxiv.org/abs/2307.09288). Namely, we replace
older BERT-like building blocks with their improved equivalent, namely,
we:
- Replace the old positional encoding with [“rotary positional
embeddings”](https://huggingface.co/blog/designing-positional-encoding)
(RoPE): this makes the model much better at understanding where words
are in relation to each other, and allows us to scale to longer
sequence lengths.
- Switch out the old MLP layers for GeGLU layers, improving on the
original BERT’s GeLU activation function.
- Streamline the architecture by removing unnecessary bias terms,
letting us spend our parameter budget more effectively
- Add an extra normalization layer after embeddings, which helps
stabilize training
### Upgrading a Honda Civic for the Race Track
We’ve covered this already: encoders are no Ferraris, and ModernBERT is
no exception. However, that doesn’t mean it can’t be fast. When you get
on the highway, you generally don’t go and trade in your car for a race
car, but rather hope that your everyday reliable ride can comfortably
hit the speed limit.
In fact, for all the application cases we mentioned above, speed is
essential. Encoders are very popular in uses where they either have to
process tons of data, allowing even tiny speed increments to add up very
quickly, or where latency is very important, as is the case on RAG. In a
lot of situations, encoders are even run on CPU, where efficiency is
even more important if we want results in a reasonable amount of time.
As with most things in research, we build while standing on the
shoulders of giants, and heavily leverage Flash Attention 2’s speed
improvements. Our efficiency improvements rely on three key components:
**Alternating Attention**, to improve processing efficiency, **Unpadding
and Sequence Packing**, to reduce computational waste, and
**Hardware-Aware Model Design**, to maximise hardware utilization.
#### Global and Local Attention
One of ModernBERT’s most impactful features is **Alternating**
**Attention**, rather than full global attention. In technical terms,
this means that our attention mechanism only attends to the full input
every 3 layers (**global attention**), while all other layers use a
sliding window where every token only attends to the 128 tokens nearest
to itself (**local attention)**.
As attention’s computational complexity balloons up with every
additional token, this means ModernBERT can process long input sequences
considerably faster than any other model.
In practice, it looks like this:
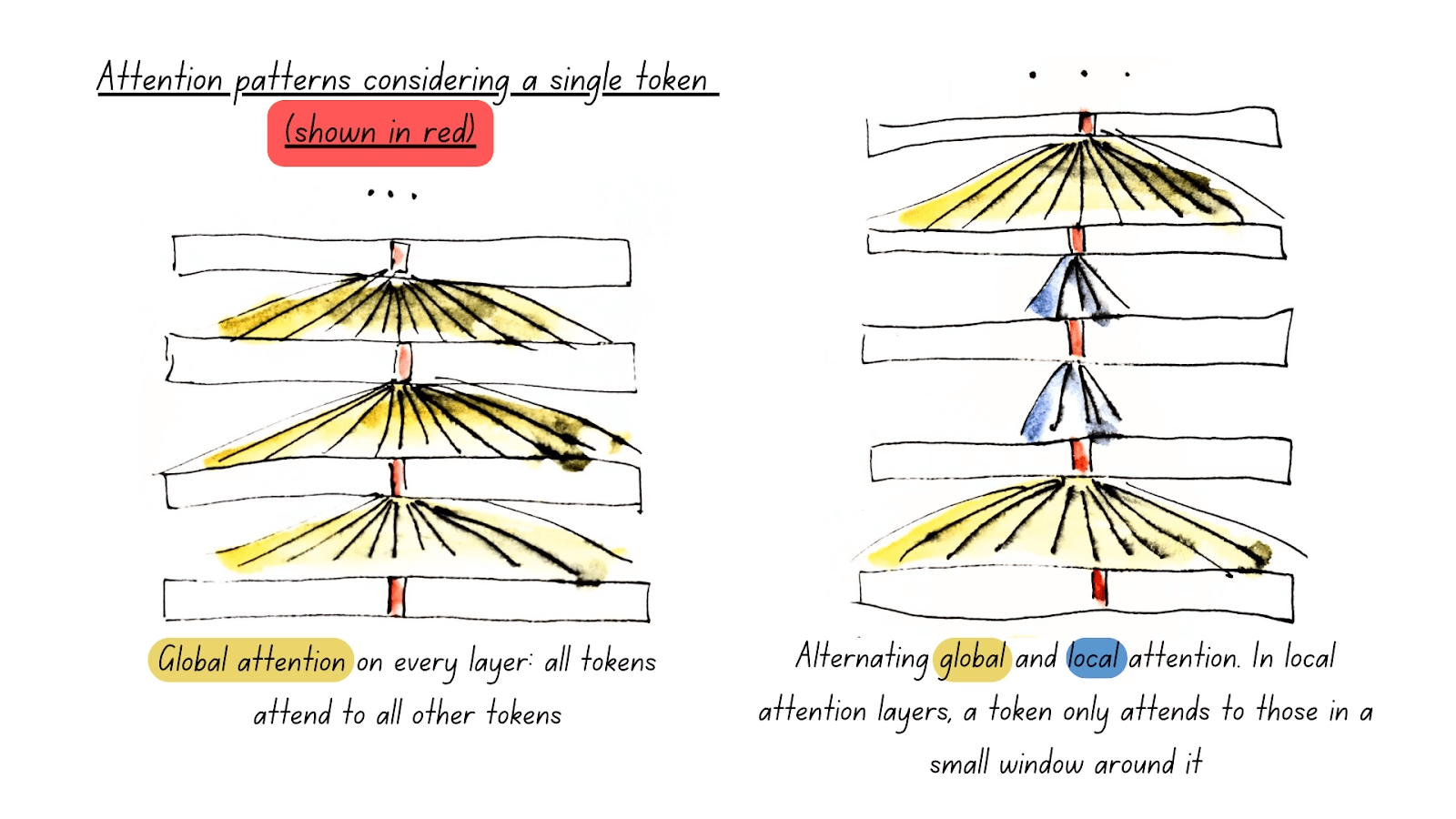
Conceptually, the reason this works is pretty simple: Picture yourself
reading a book. For every sentence you read, do you need to be fully
aware of the entire plot to understand most of it (**full global
attention**)? Or is awareness of the current chapter enough (**local
attention**), as long as you occasionally think back on its significance
to the main plot (**global attention**)? In the vast majority of cases,
it’s the latter.
#### Unpadding and Sequence Packing
Another core mechanism contributing to ModernBERT’s efficiency is its
use for Unpadding and Sequence packing.
In order to be able to process multiple sequences within the same batch,
encoder models require them to be the *same length*, so they can perform
parallel computation. Traditionally, we’ve relied on **padding** to
achieve this: figure out which sentence is the longest, and add
meaningless tokens (*padding tokens*) to fill up every other sequence.
While padding solves the problem, it doesn’t do so elegantly: a lot of
compute ends up being spent and wasted on padding tokens, which do not
contribute any semantic information.
Comparing padding with sequence packing.
Sequence packing (‘unpadding’) avoids wasting compute on padding tokens
and has more consistent non-padding token counts per batch. Samples are
still processed individually through careful masking.
**Unpadding** solves this issue: rather than keeping these padding
tokens, we remove them all, and concatenate them into mini-batches with
a batch size of one, avoiding all unnecessary computations. If you’re
using Flash Attention, our implementation of unpadding is even faster
than previous methods, which heavily relied on unpadding and repadding
sequences as they went through the model: we go one step further by
introducing our own implementation of unpadding, relying heavily on
recent developments in Flash Attention’s RoPE support. This allows
ModernBERT to only have to unpad once, and optionally repad sequences
after processing, resulting in a 10-20% speedup over previous methods.
To speed up pre-training even further, unpadding is in good company
within our model, as we use it in conjunction with **sequence packing.**
Sequence packing here is a logical next step: as we’re concatenating
inputs into a single sequence, and GPUs are very good at
parallelisation, we want to maximise the computational efficiency we can
squeeze out of a single forward model pass. To do so, we use a greedy
algorithm to group individual sequences into concatenated ones that are
as close to the model’s maximum input length as possible.
#### Paying Attention to Hardware
Finally, the third facet of ModernBERT’s efficiency is hardware design.
We attempted to balance two insights that have been highlighted by
previous research:
1. *Deep & Narrow vs Wide & Shallow*: [Research
shows](https://arxiv.org/abs/2109.10686) that deeper models with
narrower layers, often perform better than shallow models with
fewer, wider layers. However, this is a double-edged sword: the
deeper the model, the less parallelizable it becomes, and thus, the
slower it runs at identical parameter counts.
2. *Hardware Efficiency*: Model dimensions need to align well with GPU
hardware for maximum performance, and different target GPUs result
in different constraints.
Sadly, there is no magic recipe to make a model run similarly well on a
wide range of GPUs, but there is an excellent cookbook: [*The Case for
Co-Designing Model Architectures with
Hardware*](https://arxiv.org/abs/2401.14489), in which the ways to
optimize a model architecture for a given GPU are carefully laid out. We
came up with a heuristic to extend their method to a basket of GPUs,
while respecting a given set of constraints. Logically, the first step
is to define said constraints, in our case:
- Defining our target GPUs as common inference ones (RTX 3090/4090, A10,
T4, L4)
- Roughly defining our target model sizes at 130-to-150 million
parameters for ModernBERT-Base, and 350-to-420 for ModernBERT-Large.
- The final embedding sizes must match the original BERT’s dimensions,
768 for base and 1024 for large, to maximize backwards compatibility
- Set performance constraints which are common across the basket of GPUs
Afterwards, we experimented with multiple model designs via a
constrained grid search, varying both layer counts and layer width. Once
we’d identified shapes that appeared to be the most efficient ones, we
confirmed that our heuristics matched real-world GPU performance, and
settled on the final model designs.
### Training
#### def data(): return \[‘text’, ‘bad_text’, ‘math’, ‘code’\]
Picture this exact scene, but replace
Developers with Data
Another big aspect in which encoders have been trailing behind is
training data. This is often understood to mean solely training data
**scale**, but this is not actually the case: previous encoders, such as
DeBERTaV3, were trained for long enough that they might have even
breached the trillion tokens scale!
The issue, rather, has been training data **diversity**: many of the
older models train on limited corpora, generally consisting of Wikipedia
and Wikibooks. These data mixtures are very noticeably **single text
modality**: they contain nothing but high-quality natural text.
In contrast, ModernBERT is trained on data from a variety of English
sources, including web documents, code, and scientific articles. It is
trained on **2 trillion tokens**, of which most are unique, rather than
the standard 20-to-40 repetitions common in previous encoders.
The impact of this is immediately noticeable: out of all the existing
open source encoders, ModernBERT is in a class of its own on
programming-related tasks. We’re particularly interested in what
downstream uses this will lead to, in terms of improving programming
assistants.
#### Process
We stick to the original BERT’s training recipe, with some slight
upgrades inspired by subsequent work: we remove the Next-Sentence
Prediction objective, since then shown to add overhead for no clear
gains, and increase the masking rate from 15% to 30%.
Both models are trained with a **three-phase process**. First, we train
on 1.7T tokens at a sequence length of 1024. We then adopt a
long-context adaptation phase, training on 250B tokens at a sequence
length of 8192, while keeping the total tokens seen per batch more or
less consistent by lowering the batch size. Finally, we perform
annealing on 50 billion tokens sampled differently, following the
long-context extension ideal mix highlighted by
[ProLong](https://arxiv.org/abs/2410.02660).
Training in three phases is our way of ensuring our model is good across
the board, which is reflected in its results: it is competitive on
long-context tasks, at no cost to its ability to process short context…
… But it has another benefit: for the first two-phases, we train using a
constant learning rate once the warmup phase is complete, and only
perform learning rate decay on the final 50 billion tokens, following
the Trapezoidal (or Warmup-Stable-Decay) learning rate. And what’s more:
we will release every single immediate intermediate checkpoints from
these stable phases, inspired by
[Pythia](https://arxiv.org/abs/2304.01373). Our main reason for doing so
was supporting future research and applications: **anyone is free to
restart training from any of our pre-decay checkpoints, and perform
annealing on domain-appropriate data for their intended use**!
#### The tricks, it’s all about the tricks!
If you’ve made it this far into this announcement, you’re probably used
to this: of course, we use tricks to make things quicker here too. To be
precise, we have two main tricks.
Let’s start with the first one, which is pretty common: since the
initial training steps are updating random weights, we adopt
**batch-size warmup:** we start with a smaller batch size so the same
number of tokens update the model weights more often, then gradually
increase the batch size to the final training size. This significantly
speeds up the initial phase of model training, where the model learns
its most basic understanding of language.
The second trick is far more uncommon: **weight initialization via
tiling for the larger model size**, inspired by Microsoft’s
[Phi](https://azure.microsoft.com/en-us/products/phi) family of models.
This one’s based on the following realization: Why initialize the
ModernBERT-large’s initial weights with random numbers when we have a
perfectly good (if we dare say so ourselves) set of ModernBERT-base
weights just sitting there?
And indeed, it turns out that tiling ModernBERT-base’s weights across
ModernBERT-large works better than initializing from random weights. It
also has the added benefit of stacking nicely with batch size warmup for
even faster initial training.
## Conclusion
In this blog post we introduced the ModernBERT models, a new
state-of-the-art family of small and efficient encoder-only models,
finally giving BERT a much needed do-over.
ModernBERT demonstrates that encoder-only models can be improved by
modern methods. They continue to offer very strong performance on some
tasks, providing an extremely attractive size/performance ratio.
More than anything, we’re really looking forward to seeing what creative
ways to use these models the community will come up with! To encourage
this, we’re opening a call for demos until January 10th, 2025: the 5
best ones will get added to this post in a showcase section and win a
$100 (or local currency equivalent) Amazon gift card, as well as a
6-month HuggingFace Pro subscription! If you need a hint to get started,
here’s a demo we thought about: code similarity HF space! And remember,
this is an encoder model, so all the coolest downstream applications
will likely require some sort of fine-tuning (on real or perhaps
decoder-model synthetic data?). Thankfully, there’s lots of cool
frameworks out there to support fine-tuning encoders:
[🤗Transformers](https://huggingface.co/docs/transformers/en/index)
itself for various tasks, including classification,
[GliNER](https://github.com/urchade/GLiNER) for zero-shot Named Entity
Recognition, or [Sentence-Transformers](https://sbert.net/) for
retrieval and similarity tasks!
## Links
- [🤗ModernBERT-Base](https://huggingface.co/answerdotai/ModernBERT-base)
- [🤗ModernBERT-Large](https://huggingface.co/answerdotai/ModernBERT-large)
- [📝arXiv](https://arxiv.org/abs/2412.13663)
- [🤗ModernBERT documentation
page](https://huggingface.co/docs/transformers/main/en/model_doc/modernbert)
*LightOn sponsored the compute for this project on Orange Business Cloud
Avenue.*

