rerankers: A Lightweight Python Library to Unify Ranking Methods
TL;DR
We’ve released (a while ago, now, with no further report of any major issues, warranting this blog post!) rerankers, a low-dependency Python library to provide a unified interface to all commonly used re-ranking models. It’s available on GitHub here.
In this post, we quickly discuss:
- Why two-stage pipelines are so popular, and how they’re born of various trade-offs.
- The various methods now commonly used in re-ranking.
rerankersitself, its design philosophy and how to use it.
Introducing rerankers: why and how?
In Information Retrieval, the use of two-stage pipelines is often regarded as the best approach to maximise retrieval performance. In effect, this means that a small set of candidate documents is first retrieved by a computationally efficient retrieval method, to then be re-scored by a stronger, generally neural network-based, model. This latter stage is widely known as re-ranking, as the list of retrieved documents is re-ordered by the second model.
However, using re-ranking models is often more complex than it needs to be. For a starter, there is a lot of methods, with their different pros and cons, and it’s often difficult to know which one is the best for a given use case. This issue is compounded by the fact that most of these methods are implemented in sometimes wildly different code-bases. As a result, trying out different approaches can require a non-trivial amount of work, which would be better spent in other areas.
A while back, I posted a quick overview of the “best starter re-ranking model” for every use case, based on latency requirements and environment constraints on Twitter, to help people get started in their exploration. It got unexpectedly popular, as it’s quite a difficult environment to map. Below is an updated version of that chart, incorporating a few new models, including our very own answerdotai/answer-colbert-small-v1:
As you can see, even figuring out your starting point can be complicated! In production situations, this often means that re-ranking gets neglected, as the first couple solutions are make-or-break: either they’re “good enough” and get used, even if suboptimal, or they’re not good enough, and re-ranking gets relegated to future explorations.
To help solve this problem, we introduced the rerankers library. rerankers is a low-dependency, compact library which aims to provide a common interface to all commonly used re-ranking methods. It allows for easy swapping between different methods, with minimal code changes, while keeping a unified input/output format. rerankers is designed with extensibility in mind, making it very easy to add new methods, which can either be re-implementations, or simply a wrapper for existing code-bases.
In this blog post, inspired by our rerankers demo paper, we’ll discuss: 1. Why two-stage pipelines are so popular, and how they’re born of various trade-offs. 2. The various methods commonly used in re-ranking 3. rerankers itself, how to use it and its design philosophy
Two-Stages, why?
So, why exactly are two-stage pipelines so popular? What makes it so that we need to break the retrieval step into two sub-steps, rather than having a single, all-powerful search?
The problem essentially boils down to the trade-off between performance and efficiency. The most common way to do retrieval is to use a lightweight approach, either keyword-based (BM25), or based on neural-network generated embeddings. In the case of the latter, you will simply embed your query with the same model that you previously embedded your documents with, and will use cosine similarity to measure how “relevant” certain documents are to the query: this is what gets called “vector search”.
In the case of both keyword-based retrieval and vector search, the computational cost of the retrieval step is extremely low: you, at most, need to run inference for a single, most likely short, query, and very computationally cheap similarity computations. However, this comes at a cost: this retrieval step is performed in a “cold” way: your documents were processed a long time ago, and their representations are frozen in time. This means that they’re entirely unaware of the information you’re looking for with your query, making the task harder, as the model is expected to be able to represent both documents and queries in a way that’ll make them easily comparable. Moreover, it has to do so without even knowing what kind of information we’ll be looking for!
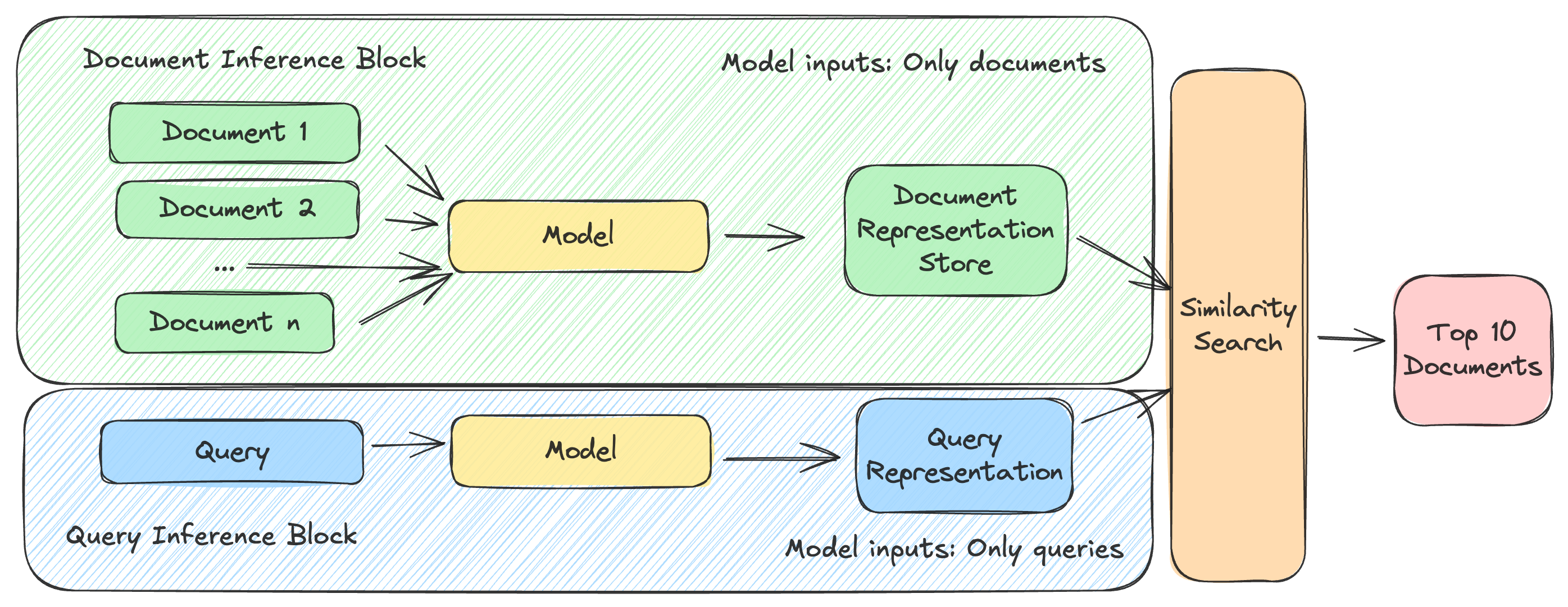
This is where re-ranking comes in. A ranking model, typically, will always consider both queries and documents at inference-time, and will accordingly rank the documents by relevance. This is great: your model is both query-aware and document-aware at inference time, meaning it can capture much more fine-grained interactions between the two. As a result, it can capture nuances that your query might require which would otherwise be missed.
However, the computational cost is steep: in this set-up, representations cannot be pre-computed, and inference must be run on all potentially relevant documents. This makes this kind of model completely unsuitable for any sort of large, or even medium, scale retrieval task, as the computational cost would be prohibitive.
You can probably see where I’m going with this, now: why not combine the two? If we’ve got families of models that are able to very efficiently retrieve potentially relevant documents, and another set of models which are much less efficient, but able to rank documents more accurately, why not use both?
By using the former, you can generate a much more restricted set of candidate documents, by fetching the 10, 50, or even 100 most “similar” documents to your query. You can then use the latter to re-rank this manageable-sized set of documents, to produce your final ordered ranking:
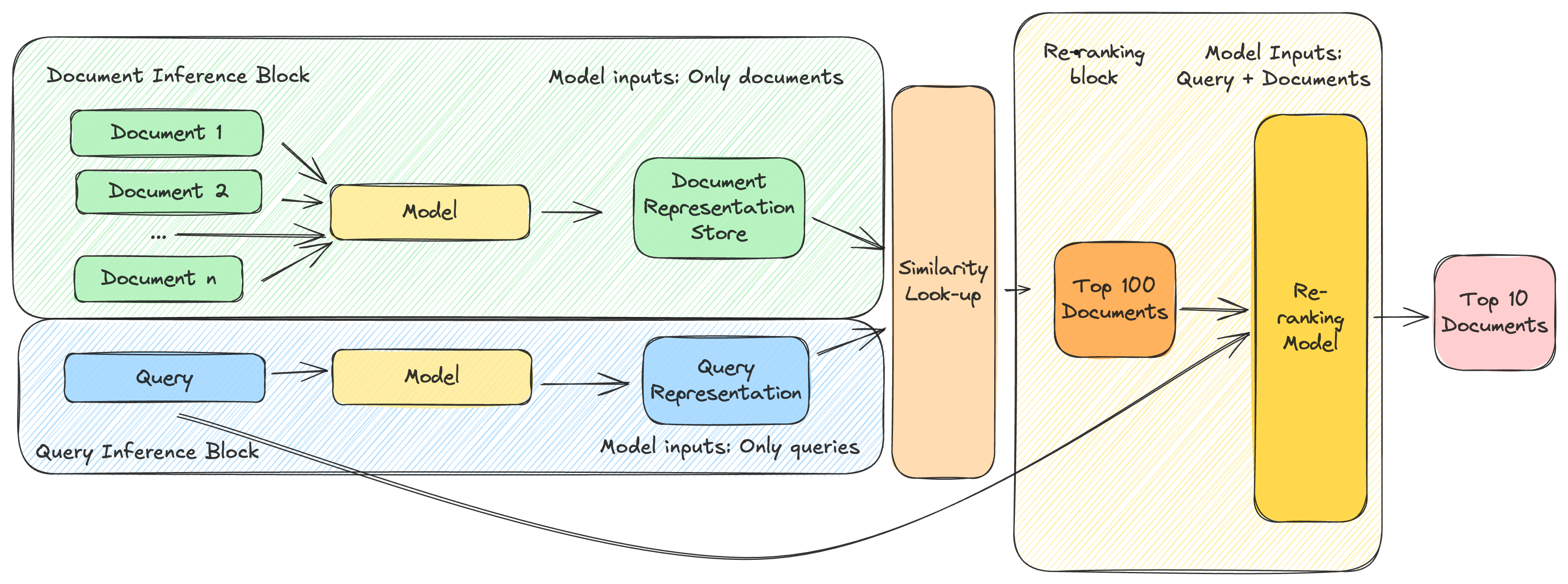
This is essentially what two-stage pipelines boil down to: they work around the trade-offs of various retrieval approaches to produce the best possible final ranking, with fast-but-less-accurate retrieval models feeding into slow-but-more-accurate ranking models.
The many faces of re-ranking
With this being said, there’s another aspect to discuss to understand why rerankers is useful: the different types of re-ranking models that exist.
For a long time, re-ranking was dominated by cross-encoder models, which are essentially just binary sentence classification models, using BERT-like models: these models are given both the query and a document as input, and they output a “relevance” score for the pair, which is the probability it assigns to the positive class. This approach, outputting a score for each query-document pair, is called Pointwise re-ranking.
However, as time went on, an increasing number of new, powerful re-ranking methods have merged. One such example is MonoT5, where the model is trained to output a “relevant” or “irrelevant” token, with the likelihood of the “relevant” token being outputted being used as a relevance score. This line of work has recently been revisited with LLMs, with models such as BGE-Gemma2 calibrating a 9 billion parameter model to output relevance scores through the log-likelihood of the “relevant” token.
Another example is the use of late-interaction retrieval models, such as our own answerdotai/answer-colbert-small-v1 (read more about it here), repurposed as re-ranking models.
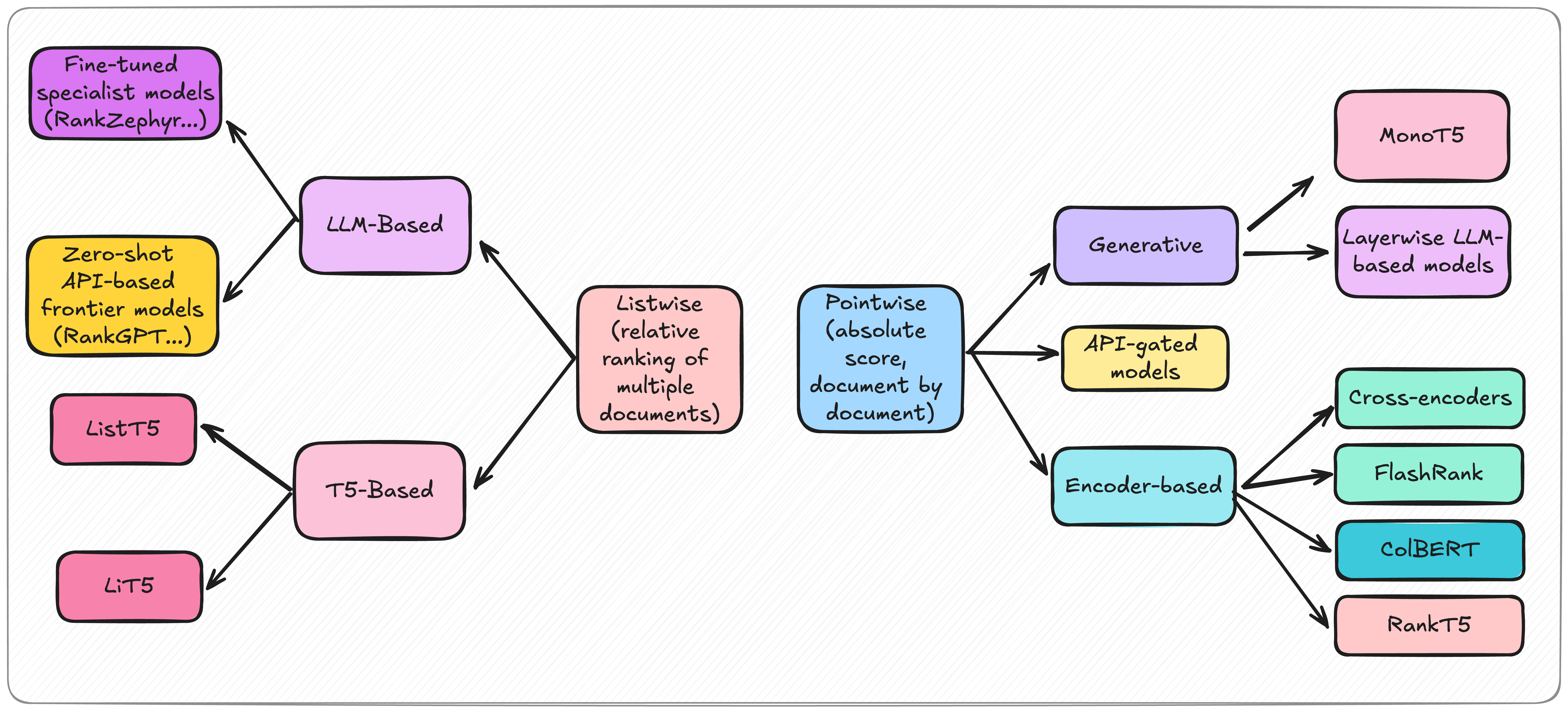
Other methods do not directly output relevance scores, but simply re-order documents by relevancy. These are called Listwise methods: they take in a list of documents, and re-output the document with an updated order, based on relevance. This has traditionally been done using T5-based models. However, recent work is now exploring the use of LLMs for this, either in a zero-shot fashion (RankGPT), or by fine-tuning smaller models on the output of frontier models (RankZephyr).
Ultimately, this section could go on for much longer: the main point is that there exist many different approaches to re-ranking, each with their own pros and cons. The more annoying truth is also that there currently is no silver bullet re-ranking method that’ll work for all use cases: you have to figure out exactly which one works best for your situation (and sometimes, that even involves fine-tuning your own!). Even more annoying is that doing so requires quite a lot of code iteration, as most of the methods listed above are not implemented in a way that’ll allow for easy swapping out of one for another. They all expect inputs formatted in a certain way while also outputting scores in their own way.
This leads us to the main point of rerankers: it aims to provide a common interface to all of these methods, making it easy to try out different approaches and find the best one for your use case.
rerankers
Now that we’ve established the why of rerankers, let’s discuss how it actually works.
rerankers as a library follows a clear design philosophy, with a few key points:
- As with our other retrieval libraries, RAGatouille and Byaldi, the goal is to be fully-featured while requiring the fewest lines of code possible.
- It aims to provide support for all common re-ranking methods, through a common interface, without any retrieval performance degradation compared to official implementations.
rerankersmust be lightweight and modular. It is low-dependency, and it should allow users to only install the dependencies required for their chosen methods.- It should be easy to extend. It should be very easy to add new methods, whether they’re custom re-implementations, or wrappers around existing libraries.
In practice, these objectives are achieved by structuring the application around just two main exposed classes: the Reranker class, which is the main class used to perform re-ranking, and RankedResults, itself containing a list Result, which are fully-transparent objects used to store results along with associated useful information.
Reranker
Every method supported by rerankers is implemented around the Reranker class. It is used as the main interface to load models, no matter the underlying implementation or requirements.
You can initialise a Reranker with a model name or path, with full HuggingFace Hub support, and a model_type parameter, which specifies the type of model you’re loading. By default, a Reranker will attempt to use the GPU and half-precision if available on your system, but you can also pass a dtype and device (when relevant) to further control how the model is loaded. API-based methods can be passed an API_KEY, although the better way is to use the API provider’s preferred environment variable.
Loading a Reranker is very straightforward:
# Initialising a BERT-like cross-encoder model
ranker = Reranker(MODEL_NAME_OR_PATH, model_type='cross-encoder')
# MonoT5-based models, with a specified dtype
ranker = Reranker(MODEL_NAME_OR_PATH, model_type = "t5", dtype=torch.float32)
# Flashrank models, with a specified device
ranker = Reranker(MODEL_NAME_OR_PATH, model_type='flashrank', device="cpu")
# ... and so onOnce loaded, the class has a single exposed method, rank(), which takes in a query and a set of documents. No matter the underlying implementation, it will return a RankedResults object containing the re-ranked documents. Using rank() is just as straightforward as loading the model:
# Every Reranker then has a single `rank` method, which performs inference.
results = ranker.rank(query="Who wrote Spirited Away?", docs=["Spirited Away [...] is a 2001 Japanese animated fantasy film written and directed by Hayao Miyazaki. ", "Lorem ipsum..."], doc_ids=[0,1])RankedResults
Similarly to how Reranker serves as a single interface to various models, RankedResults objects are a centralised way to represent the outputs of various models, themselves containing Result objects. Both RankedResults and Result are fully transparent, allowing you to iterate through RankedResults and retrieve their associated attributes.
RankedResults and Result’s main aim is to serve as a helper. Most notably, each Result object stores the original document, as well as the score outputted by the model, in the case of pointwise methods. They also contain the document ID, and, optionally, document meta-data, to facilitate usage in production settings. The output of rank() is always a RankedResults object, and will always preserve all the information associated with the documents:
# Ranking a set of documents returns a RankedResults object, preserving meta-data and document-ids.
results = ranker.rank(query="I love you", docs=["I hate you", "I really like you"], doc_ids=[0,1], metadata=[{'source': 'twitter'}, {'source': 'reddit'}])
results
> RankedResults(results=[Result(document=Document(text='I really like you', doc_id=1, metadata={'source': 'twitter'}), score=-2.453125, rank=1), Result(document=Document(text='I hate you', doc_id=0, metadata={'source': 'reddit'}), score=-4.14453125, rank=2)], query='I love you', has_scores=True)You will notice that RankedResults’s main purpose is to contain Result objects in an easily accessible way, but it also has two useful meta-attributes: query, which contains the text of the original query, and has_scores, which allows you to easily check whether or not the re-ranking method you’re using actually outputs scores, or just re-orders documents.
While you can directly iterate through RankedResults, you can also use it to directly access information that is useful for various use cases: via the top_k method, you can directly retrieve only the top k results, which is useful if you’re only interested in the most relevant documents:
# RankedResults comes with various built-in functions for common uses, such as .top_k(), and all attributes are accessible:
results.top_k(1).text
> 'I really like you'Alternatively, if you’re using the library to generate scores for distillation purposes, you can also directly fetch the score of any given [query, document] pair by calling get_score_by_docid(doc_id) on the appropriate document id:
# It's also possible to directly fetch the score given to a single document
results.get_score_by_docid(0)
> -4.14453125Modularity & Extensibility
Modularity rerankers is designed specifically with ease of extensibility in mind. All approaches are independently-implemented and have individually-defined sets of dependencies, which users are free to install or not based on their needs. Informative error messages are shown when a user attempts to load a model type that is not supported by their currently installed dependencies.
Extensibility As a result, adding a new method simply requires making its inputs and outputs compatible with the rerankers-defined format, as well as a simple modification of the main Reranker class to specify a default model. This approach to modularity has allowed us to support all the approaches with minimal engineering efforts. We fully encourage researchers to integrate their novel methods into the library and will provide support for those seeking to do so.
rerankers within the ecosystem
rerankers‘s main aim is to act as a unifying re-ranking inference interface, which suits the needs of both researchers and practitioners. Up until now, we are not aware of any library with a similar aim to rerankers: as such, it is not intended to compete with any existing libraries. While extensive IR frameworks, such as PyTerrier or Pyserini do exist, they largely focus on reproducible research use cases, leading to a very different design philosophy from rerankers’ low footprint approach.
Finally, rerankers aims to always preserve the performance of the methods it implements. In some cases, the backend implementation is the official one, ensuring full performance parity. In other cases, rerankers implementation may be a simplified one, removing unnecessary dependencies and components. In these cases, we conducted top-1000 reranking evaluations on three commonly used datasets1.
For most models within the library, we achieve performance parity with the existing implementation code and reported results from the literature. A notable exception is RankGPT, where our results over all runs were noticeably different from the paper’s reported results2. However, the official implementation’s results largely matched our own during our runs. This likely indicates that the issue is not with our implementation, but the general difficulty of reproducing experiments conducted with unreleased, API-only models such as the GPT family.
Takeaways
I originally hoped that I could delegate this bit to tabtabtabtabtab Cursor, but it very quickly became apparent that Homer Simpson it is not the markdown genius I thought it was:

Anyway, here are the quick take-aways from this blog post:
- Two-stage pipelines are popular, because they let you use strong models that can capture finer aspects of your query-document relationships, which would be prohibitively slow if used on their own.
- There are a lot of different approaches to re-ranking, and we’ve only covered the main and most recent ones!
- On top of there being a lot, there’s no cookie-cutter answer: as with all things retrieval, it very much depends on your data and your use case.
- We introduce
rerankersto help you navigate this ecosystem: now, you can use (most) of the fancy re-ranking methods with a single, low-dependency library! All it takes to re-rank documents is two lines of code, and switching between methods is as simple as changing a couple parameters in your model loading call. rerankersis built to easily slot-in anywhere, and support new methods really easily. In fact, there’s already some academic work which has madererankersits official re-ranking codebase!rerankersis open-source and available at github.com/answerdotai/rerankers.