# Small but Mighty: Introducing answerai-colbert-small
Benjamin Clavié
2024-08-13
A couple weeks ago, we released
[JaColBERTv2.5](https://www.answer.ai/posts/2024-08-02-jacolbert-v25.html),
using an updated ColBERT training recipe to create the state-of-the-art
Japanese retrieval model.
Today, we’re introducing a new model, [answerai-colbert-small-v1
(🤗)](https://huggingface.co/answerdotai/answerai-colbert-small-v1), a
proof of concept for smaller, faster, modern ColBERT models. This new
model builds upon the JaColBERTv2.5 recipe and has just **33 million
parameters**, meaning it’s able to search through hundreds of thousands
of documents in milliseconds, **on CPU**.
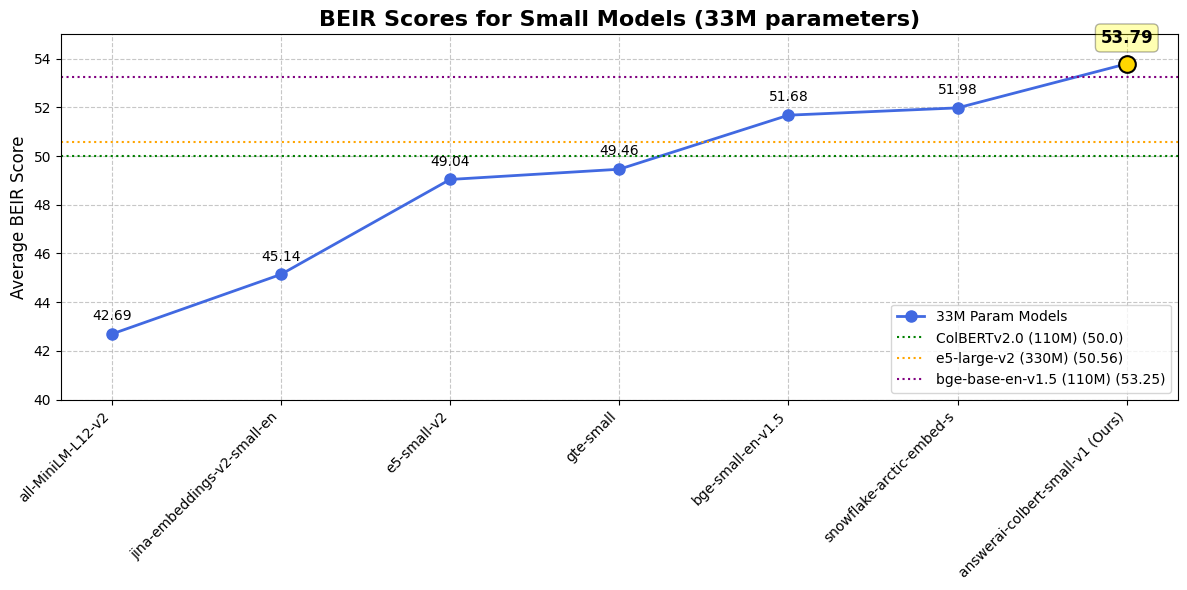
Despite its small size, it’s a particularly strong model, vastly
outperforming the original 110 million parameters ColBERTv2 model on all
benchmarks, even ones completely unseen during training such as LoTTe.
In fact, it is by far the best performing model of its size on common
retrieval benchmarks, and it even outperforms some widely used models
that are 10 times larger, such as `e5-large-v2`:
Performance comparison of
answerai-colbert-small-v1 against other similarly sized models, with
widely used models as reference points.
Of course, benchmarking is very far from perfect, and nothing beats
trying it on your own data! However, if you’re interested in more
in-depth results, and what they might mean, you can jump directly to the
[Evaluation](#evaluation) section.
We believe that with its strong performance and very small size, this
model is perfect for latency-sensitive applications or for quickly
retrieving documents before a slower re-ranking step. Even better: it’s
extremely cheap to fine-tune on your own data, and [training data has
never been easier to generate, even with less than 10 human-annotated
examples](https://arxiv.org/abs/2406.11706).
*And with the upcoming
[🪤RAGatouille](https://github.com/answerdotai/ragatouille) overhaul,
it’ll be even easier to fine-tune and slot this model into any pipeline
with just a couple lines of code!*
## The Recipe
We’ll release a technical report at some point in the future, and a lot
of the training recipe is identical to JaColBERTv2.5’s, with different
data proportions, so this section will focus on just a few key points.
We conducted relatively few ablation runs, but tried to do so in a way
that wouldn’t reward overfitting. As a validation set, we used the
development set of NFCorpus, as well as
[LitSearch](https://huggingface.co/datasets/princeton-nlp/LitSearch) and
a downsample of the LoTTe Lifestyle subset, which was used to evaluate
ColBERTv2.
### Why so tiny?
As our goal was to experiment quickly to produce a strong proof of
concept, we focused on smaller models in the `MiniLM`-size range, which
is generally just called `small` in the embedding world: around 33M
parameters. This size has multiple advantages:
- It is very quick to train, resulting in faster experimentation.
- It results in very low querying latency, making it suitable for the
vast majority of applications.
- Inference comes with a cheap computational cost, meaning it can
comfortably be deployed on CPU.
- It’s very cheap to fine-tune, allowing for easy domain adaptation,
with recent research showing ColBERT models fine-tune on fully
synthetic queries with great success.
- It does all this while still achieving performance that vastly
outperforms state-of-the-art 350M parameter models from just a year
ago.
### Starting strong
The first base model candidate was the original
[MiniLM](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased)
model, which is a distilled version of BERT-base.
However, applied information retrieval is, largely, an entire ecosystem.
There are a lot of strong models, which exists, and on which we can
build, to avoid re-building the wheel from scratch everytime we want to
make a faster car. Starting from MiniLM meant just that: a very large
amount of our training compute, and therefore data, would be sent just
bringing the model’s vector space over from its MLM pre-training
objective to one better suited for semantic retrieval.
As a result, we experimented with a few other candidates, picking 33M
parameters embedding models which performed decently on existing
benchmarks, but without quite topping them: Alibaba’s
[gte-small](https://huggingface.co/thenlper/gte-small) and BAAI’s
[bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5).
Finally, in line with the JaColBERTv2.5 approach, where model merging
featured prominently, we also experimented with a model we simply called
`mini-base`, which is a weights-averaged version of those three
candidates.
The results of this step were pretty much as we expected: over time, no
matter the base model, the ColBERT model learns to “be ColBERT”, and
relatively similar performance on all validation steps ends up being
achieved. However, **it took nearly three times as many ablations
training steps for MiniLM to get there**, compared to starting from the
existing dense embeddings. This leads us to discard MiniLM as a base
model candidate.
Finally, as expected, `mini-base` reaches peak performance slightly
quicker than either `bge-small-en-v1.5` or `gte-small`. This leads us to
use it as our base model for the rest of our experiments and the final
model training.
### Transposing the JaColBERTv2.5 approach
The rest of our training is largely identical to the JaColBERTv2.5
recipe, with a few key differences:
**Optimizer** We do not use schedule-free training, but instead use a
linear decay schedule with 5% of the steps as a warmup. This was due to
a slight hardware support issue on the machine used for most
experiments, although we did run some ablations with schedule-free
training once another machine became available, which showed similar
results to JaColBERTv2.5, indicating it would likely be an
equal-if-not-stronger option.
**Data** The training data is obviously different. The final model is
the result of averaging the weights of three different training runs:
- The first checkpoint is the result of training on 640,000 32-way
triplets from MSMarco, with teacher scores generated by
[BGE-M3-reranker](https://huggingface.co/BAAI/bge-reranker-v2-m3).
- The second checkpoint is a further fine-tuning of the above
checkpoint, further trained on 2.5 million 32-way triplets, containing
data in equal parts from MSMarco, HotPotQA, TriviaQA, Fever and
Natural Questions. These datasets are the ones most commonly used in
the literature for English retrieval models. All the teacher scores
for this step are also generated by
[BGE-M3-reranker](https://huggingface.co/BAAI/bge-reranker-v2-m3).
- The final checkpoint is also training on 640,000 32-way triplets from
MS Marco, different from the ones above, but using the teacher scores
from [BGE’s new Gemma2-lightweight
reranker](https://huggingface.co/BAAI/bge-reranker-v2.5-gemma2-lightweight),
based on using some of the layers from the Gemma-2 model and training
them to work as a cross-encoder, using its output logits as scores.
Interestingly, individually, all of these checkpoints turned out to have
rather similar averaged downstream performance, but performed well on
different datasets. However, their averaging increased the model’s
average validation score by almost 2 points, seemingly allowing the
model to only keep its best qualities, despite its very low parameter
count.
**Data Tidbits** Some interesting findings during our limited training
data ablations:
- There appeared to be some benefit to training individually on each of
the datasets used in the second step and averaging the final
checkpoint, but the performance increase was not significant enough to
justify the additional training time.
- The above did not hold true for HotPotQA: training solely on HotPotQA
alone decreased performance on **every single metric for every single
validation dataset**. However, including it in the mix used for the
second checkpoint did result in a slight but consistent performance
boost.
- The Gemma-2 teacher scores did not improve overall results as much as
we’d hoped, but noticeably increased the results on Litsearch,
potentially suggesting that they helped the model generalise better.
Further experiments are needed to confirm or deny this. Another
potential explanation is that our negatives were not hard enough, and
the training score distribution learned by min-max normalising the
scores didn’t allow a small model to properly learn the subtleties
present in the scores generated by a much larger one.
## Evaluation
> **Tip**
>
> To help provide more vibe-aligned evaluations, the model will be
> launching on the [MTEB
> Arena](https://huggingface.co/spaces/mteb/arena) in the next few days.
This section begins with a big caveat: this is the release of a
proof-of-concept model, that we evaluate on the most common benchmarks,
and compare to other commonly used models on said benchmarks. This is
the standard practice, but it is **not a comprehensive evaluation**
Information retrieval benchmarks serve two very different purposes:
their core, original one, was to serve as a **relative comparison point
within studies** for the retrieval literature. This means, they’re
supposed to provide a good test-bed for comparing different individual
changes in methods, with all else being equal, and highlight whether or
not the proposed change represents an improvement.
Their second role, which has become the more popular one, is to allow
**absolute performance comparison between models**, by providing a
common test-bed for all models to be compared on. However, this role is
much, much harder to fill, and in a way, is practically impossible to do
perfectly. BEIR, the retrieval subset of MTEB, is a great *indicator* of
model performance, but it is fairly unlikely that it will perfectly
correlate to your specific use-case. This isn’t a slight against BEIR at
all! It’s simply a case of many factors being impossible to control for,
among which:
- Models are trained on different data mixes, which may or may not
include the training set for BEIR tasks or adjacent tasks.
- Benchmarks are frequently also used as validation sets, meaning that
they encourage training methods that will work well on them.
- Even perfectly new, non-overfitted benchmarks will generally only
evaluate a model’s performance **on a specific domain, task and query
style**. While it’s a positive signal, there is no guarantee that a
model generalising well to a specific domain or query style will also
generalise well to another.
- The ever-so-important *vibe evals* don’t always correlate with
benchmark scores.
All this to say: we think our model is pretty neat, and it does well on
standard evaluation, but what matters is **your own evaluations** and
we’re really looking forward to hearing about **how it works for you!**
### BEIR
This being said, let’s dive in, with the full BEIR results for our
model, compared to a few other commonly used models as well as the
strongest small models around.
If you’re not familiar with it,
[BEIR](https://github.com/beir-cellar/beir) is also known as the
Retrieval part of [MTEB, the Massive Text Embedding
Benchmark](https://huggingface.co/blog/mteb). It’s a collection of 15
datasets, meant to evaluate retrieval in a variety of settings (argument
mining, QA, scientific search, facts to support a claim, duplicate
detection, etc…). To help you better understand the table below, here is
a very quick summary of the datasets within it:
> **Click to expand BEIR dataset descriptions**
>
> - FiQA: QA on Financial data
> - HotPotQA: Multi-hop (might require multiple, consecutive sources)
> Trivia QA on Wikipedia
> - MS Marco: Diverse web search with real BING queries
> - TREC-COVID: Scientific search corpus for claims/questions on
> COVID-19
> - ArguAna: Argument mining dataset where the queries are themselves
> documents.
> - ClimateFEVER: Fact verification on wikipedia for claims made about
> climate change.
> - CQADupstackRetrieval: Duplicate question search on StackExchange.
> - DBPedia: Entity search on wikipedia (an entity is described,
> i.e. “Who is the guy in the Top Gun?”, and the result must contain
> Tom Cruise)
> - FEVER: Fact verification on wikipedia for claims made about general
> topics.
> - NFCorpus: Nutritional info search over PubMed (medical publication
> database)
> - QuoraRetrieval: Duplicate question search on Quora.
> - SciDocs: Finding a PubMed article’s abstract when given its title as
> the query.
> - SciFact: Find a PubMed article supporting/refuting the claim in the
> query.
> - Touche2020-v2: Argument mining dataset, [with clear flaws
> highlighted in a recent study](https://arxiv.org/abs/2407.07790).
> Only reported for thoroughness, but you shouldn’t pay much attention
> to it.
In the interest of space, we compare our model to the best
(`Snowflake/snowflake-arctic-embed-s`) and most used
(`BAAI/bge-small-en-v1.5`) 33M parameter models, as well as to the
most-used 110M parameter model (`BAAI/bge-base-en-v1.5`)[1].
Dataset / Model
answer-colbert-s
snowflake-s
bge-small-en
bge-base-en
Size
33M (1x)
33M (1x)
33M (1x)
109M (3.3x)
BEIR AVG
53.79
51.99
51.68
53.25
FiQA2018
41.15
40.65
40.34
40.65
HotpotQA
76.11
66.54
69.94
72.6
MSMARCO
43.5
40.23
40.83
41.35
NQ
59.1
50.9
50.18
54.15
TRECCOVID
84.59
80.12
75.9
78.07
ArguAna
50.09
57.59
59.55
63.61
ClimateFEVER
33.07
35.2
31.84
31.17
CQADupstackRetrieval
38.75
39.65
39.05
42.35
DBPedia
45.58
41.02
40.03
40.77
FEVER
90.96
87.13
86.64
86.29
NFCorpus
37.3
34.92
34.3
37.39
QuoraRetrieval
87.72
88.41
88.78
88.9
SCIDOCS
18.42
21.82
20.52
21.73
SciFact
74.77
72.22
71.28
74.04
Touche2020
25.69
23.48
26.04
25.7
These results show that `answerai-colbert-small-v1` is a very strong
performer, punching vastly above its weight class, even beating the most
popular `bert-base`-sized model, which is over 3 times its size!
However, the results also highlight pretty uneven performance, which
appear to be strongly related to the nature of the task. Indeed, it
performs remarkably well on datasets which are “classical” search tasks:
question answering or document search with small queries. This is very
apparent in its particularly strong MS Marco, TREC-COVID, FiQA, and
FEVER scores, among others.
On the other hand, like all ColBERT models, it struggles on less
classical tasks. For example, we find our model to be noticeably weaker
on:
- ArguAna, which focuses on finding “relevant arguments” by taking in
full, long-form (300-to-500 tokens on average) arguments and finding
similar ones, is a very noticeable weakness.
- SCIDOCS, where the nature of the task doesn’t provide the model with
very many tokens to score
- CQADupstack and Quora. These two datasets are duplicate detection
tasks, where the model must find duplicate questions on their
respective platform (StackExchange and Quora) for a given question.
This highlights the point we stated above: our model appears to be, by
far, the best model for traditional search and QA tasks. However, for
different categories of tasks, it might be a lot less well-suited.
Depending on your needs, you might need to fine-tune it, or even find a
different approach that works better on your data!
### ColBERTv2.0 vs answerai-colbert-small-v1
Finally, here’s what we’ve all been waiting for (… right?): the
comparison with the original ColBERTv2.0. Since its release, ColBERTv2.0
has been a pretty solid workhorse, which has shown extremely strong
out-of-domain generalisation, and has reached pretty strong adoption,
consistently maintaining an [average 5 million monthly downloads on
HuggingFace](https://huggingface.co/colbert-ir/colbertv2.0).
However, in the fast-moving ML world, ColBERTv2.0 is now an older model.
In the table below, you can see that our new model, with less than a
third of the parameter count, outperforms it across the board on BEIR:
Dataset / Model
answerai-colbert-small-v1
ColBERTv2.0
BEIR AVG
53.79
50.02
DBPedia
45.58
44.6
FiQA2018
41.15
35.6
NQ
59.1
56.2
HotpotQA
76.11
66.7
NFCorpus
37.3
33.8
TRECCOVID
84.59
73.3
Touche2020
25.69
26.3
ArguAna
50.09
46.3
ClimateFEVER
33.07
17.6
FEVER
90.96
78.5
QuoraRetrieval
87.72
85.2
SCIDOCS
18.42
15.4
SciFact
74.77
69.3
These results appear very exciting, as they suggest that newer
techniques, without much extensive LLM-generated data work (yet!), can
allow a much smaller model to be competitive on a wide range of uses.
But even more interestingly, they’ll serve as a very useful test of
generalisation: with our new model being so much better on benchmarks,
we hope that it’ll fare just as well in the wild on most downstream
uses.
## Final Word
This model was very fun to develop, and we hope that it’ll prove very
useful in various ways. [It’s already on the 🤗
Hub](https://huggingface.co/answerdotai/answerai-colbert-small-v1), so
you can get started right now!
We view this model as a proof of concept, for both the JaColBERTv2.5
recipe, and retrieval techniques as a whole! With its very small
parameter count, it demonstrates that there’s a lot of retrieval
performance to be squeezed out of creative approaches, such as
multi-vector models, with low parameter counts, which are better suited
to a lot of uses than gigantic 7-billion parameter embedders.
The model is ready to use as-is: it can be slotted in into any pipeline
that currently uses ColBERT, regardless of whether is it through
RAGatouille or the Stanford ColBERT codebase. Likewise, you can
fine-tune it just like you would any ColBERT model, and our early
internal experiments show that it is very responsive to in-domain
fine-tuning on even small amounts of synthetic data!
If you’re not yet using ColBERT, you can give it a go with the current
version of RAGatouille, too! In the coming weeks, we’ll also be
releasing the RAGatouille overhaul, which will make it even simpler to
use this model without any complex indexing, and, in a subsequent
release, simplify the fine-tuning process 👀.
As we mentioned, benchmarks only tell a small part of the story. We’re
looking forward to seeing the model put to use in the real world, and
see how far 33M parameters can take us!
[1] It is worth noting that recently, Snowflake’s
`Snowflake/snowflake-arctic-embed-m`, a ~110M-sized model, has reached
stronger performance that bge-base-en-v1.5, and might be a very good
choice for usecases that require a model around that size!