| Parameter | Value |
|---|---|
| Epoch | 1 |
| Precision | bf16 |
| Batch Size | 32 |
| Optimizer | AdamW |
| Learning Rate | 1e-5 |
| Learning Rate Schedule | Constant |
| Weight Decay | 0.1 |
| Context Length | 2048 |
| LoRA Rank | 64 |
| LoRA Target Modules | k_proj, q_proj, v_proj, up_proj, down_proj, gate_proj |
| Llama-Pro Expansion Rate | 0.1 |
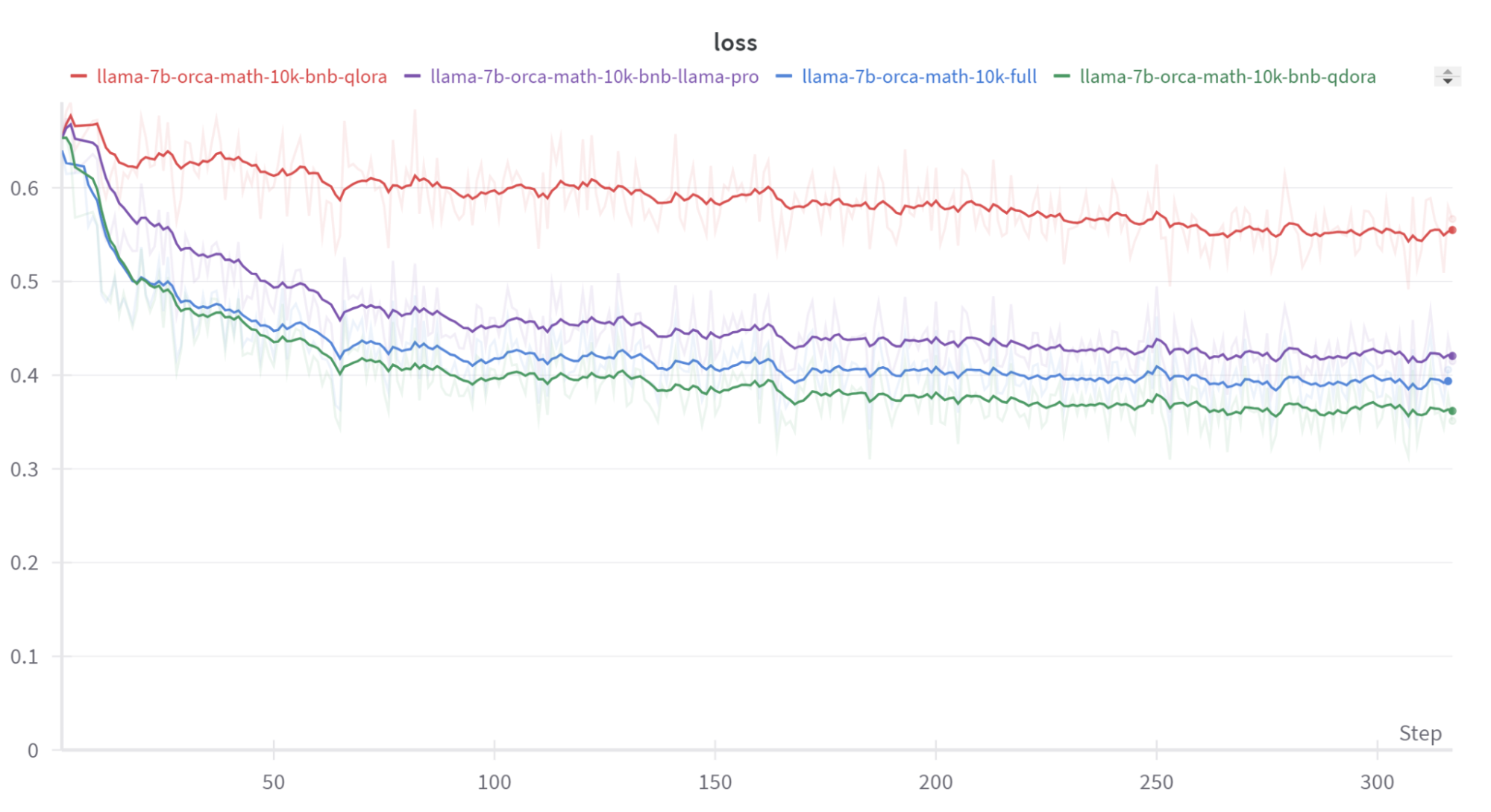
| Model | Method | Train sample size | Eval sample size | Exact match score |
|---|---|---|---|---|
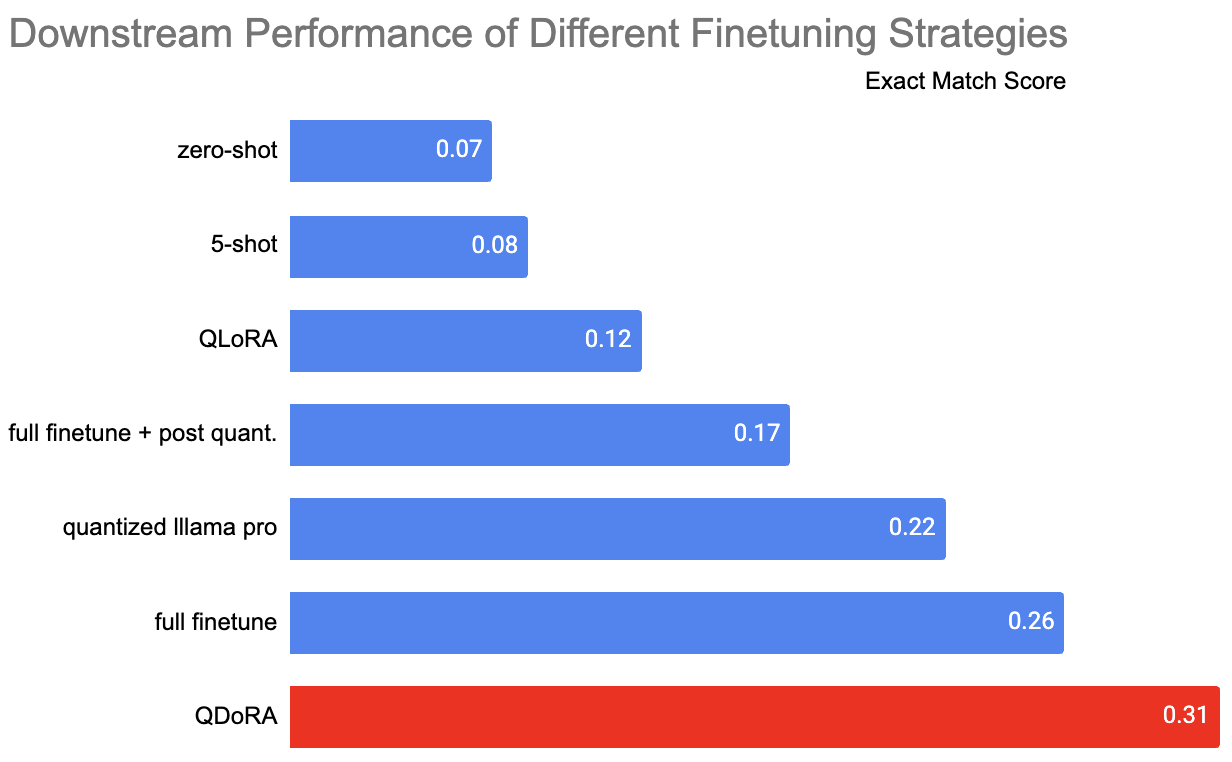
| llama-2-7b | zero-shot | - | 500 | 0.068 |
| llama-2-7b | 5-shot | - | 500 | 0.08 |
| llama-2-7b | full finetune | 10k | 500 | 0.182 |
| llama-2-7b | full finetune + post quant. | 10k | 500 | 0.14 |
| llama-2-7b | QLoRA | 10k | 500 | 0.098 |
| llama-2-7b | QDoRA | 10k | 500 | 0.176 |
| llama-2-7b | quantized llama pro | 10k | 500 | 0.134 |
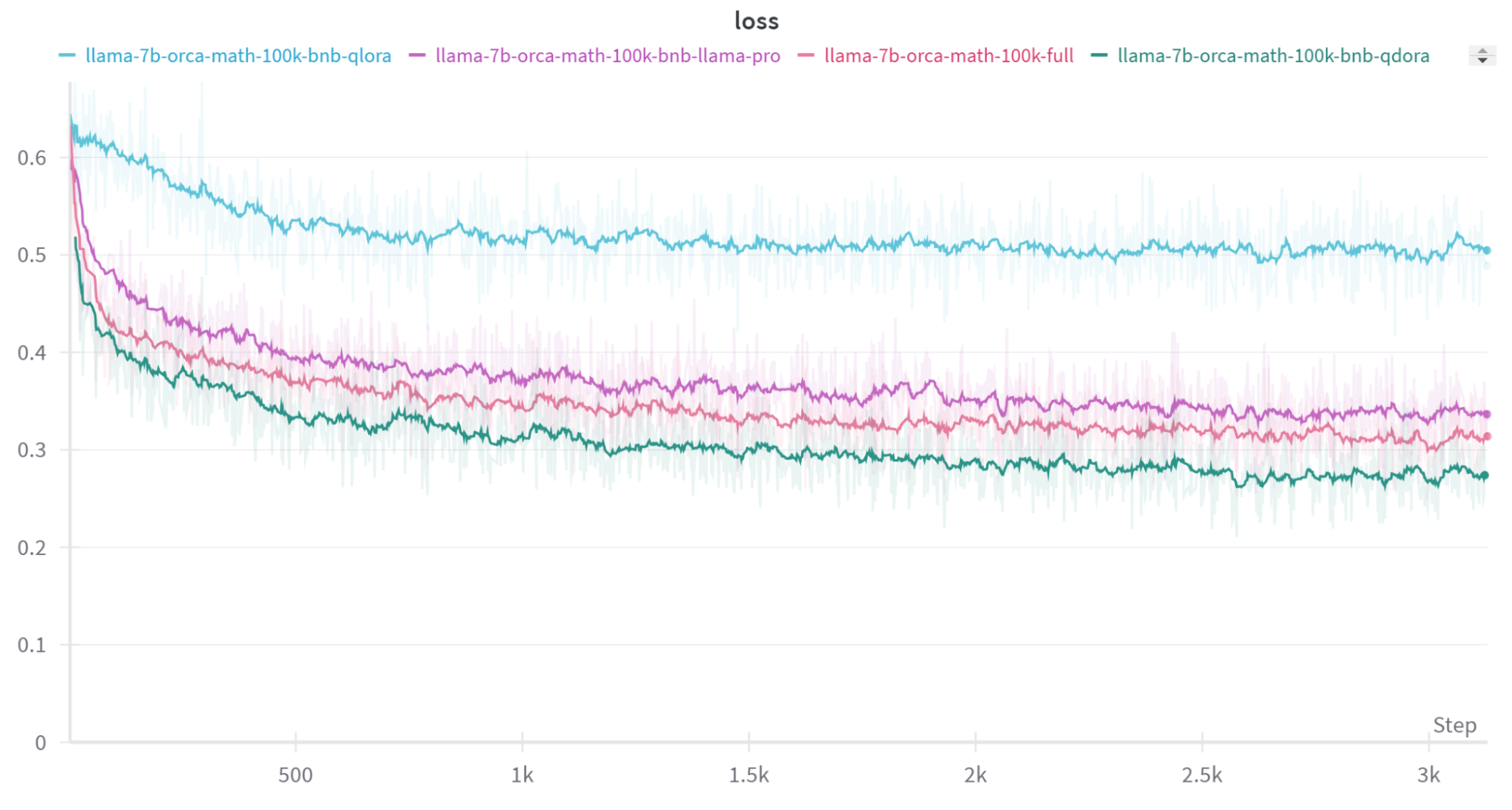
| Model | Method | Train sample size | Eval sample size | Exact match score |
|---|---|---|---|---|
| llama-2-7b | zero-shot | - | 500 | 0.068 |
| llama-2-7b | 5-shot | - | 500 | 0.08 |
| llama-2-7b | full finetune | 100k | 500 | 0.26 |
| llama-2-7b | full finetune + post quant. | 100k | 500 | 0.168 |
| llama-2-7b | QLoRA | 100k | 500 | 0.118 |
| llama-2-7b | QDoRA | 100k | 500 | 0.312 |
| llama-2-7b | quantized llama pro | 100k | 500 | 0.134 |
| Model | Compilation Mode | Model Compr. Rate | TP | Throughput (req/min) | Throughput (tok/sec) | Latency (tok/sec) | Exact match score |
|---|---|---|---|---|---|---|---|
| FFT + Post quant. | Eager | 4X | 1 | 41 | 231 | 15.6 | 0.16 |
| FFT + Post quant. | Eager | 4X | 2 | 65 | 389 | 27.5 | 0.2 |
| FFT + Post quant. | Eager | 4X | 4 | 74 | 381 | 28.1 | 0.2 |
| QDoRA BNB | Eager | 4X | 1 | 15 | 76 | 5.4 | 0.24 |
| QDoRA BNB | Eager | 4X | 2 | 27.5 | 152 | 9.9 | 0.22 |
| QDoRA BNB | Eager | 4X | 4 | 50 | 271 | 18.3 | 0.24 |
| QDoRA (merged) | CUDA Graphs | 1X | 1 | 104 | 546 | 46 | 0.42 |
| QDoRA (merged) | CUDA Graphs | 1X | 2 | 142 | 835 | 67 | 0.36 |
| QDoRA (merged) | CUDA Graphs | 1X | 4 | 172 | 1003 | 76 | 0.38 |
| QDoRA (merged) + GPTQ Marlin | CUDA Graphs | 4X | 1 | 194 | 1122 | 130 | 0.38 |
| QDoRA (merged) + GPTQ Marlin | CUDA Graphs | 4X | 2 | 200 | 1008 | 79 | 0.34 |