Efficient finetuning of Llama 3 with FSDP QDoRA
Introduction
This introductory note is from Answer.AI co-founder Jeremy Howard. The remainder of the article after this section is by Kerem Turgutlu and the Answer.AI team.
When Eric and I created Answer.AI, a key foundation of our research thesis was based on two trends we expected to see:
- A dramatic increase in the size and capability of open source models
- Much larger opportunities for finetuning these models, using “continued pre-training”. (You can learn more about my thoughts on this in my “Latent Space” podcast interview, The End of Finetuning).
A few days ago, our expectations were realized when Meta announced their Llama 3 models. The largest will have over 400 billion parameters and, although training isn’t finished, it is already matching OpenAI and Anthropic’s best LLMs. Meta also announced that they have continuously pre-trained their models at far larger scales than we’ve seen before, using millions of carefully curated documents, showing greatly improved capability from this process.
From the day we launched the company, we’ve been working on the technologies necessary to harness these two trends. Last month, we completed the first step, releasing FSDP/QLoRA, which for the first time allowed large 70b models to be finetuned on gaming GPUs. This helps a lot with handling larger models.
Today we’re releasing the next step: QDoRA. This is just as memory efficient and scalable as FSDP/QLoRA, and critically is also as accurate for continued pre-training as full weight training. We think that this is likely to be the best way for most people to train1 language models. We’ve ran preliminary experiments on Llama 2, and completed some initial ones on Llama 3. The results are extremely promising.
I expect that QDoRA with Llama 3 will allow open source developers to create better models for their tasks than anything that exists today, free or paid. Here’s a taste of the very impressive out-of-the-box results we’ve seen, showing Llama3 with QDoRA, or with full finetuning, greatly outperforming QLoRA and Llama2 when training on mathematical data (and note that full finetuning uses far more memory than the other approaches):
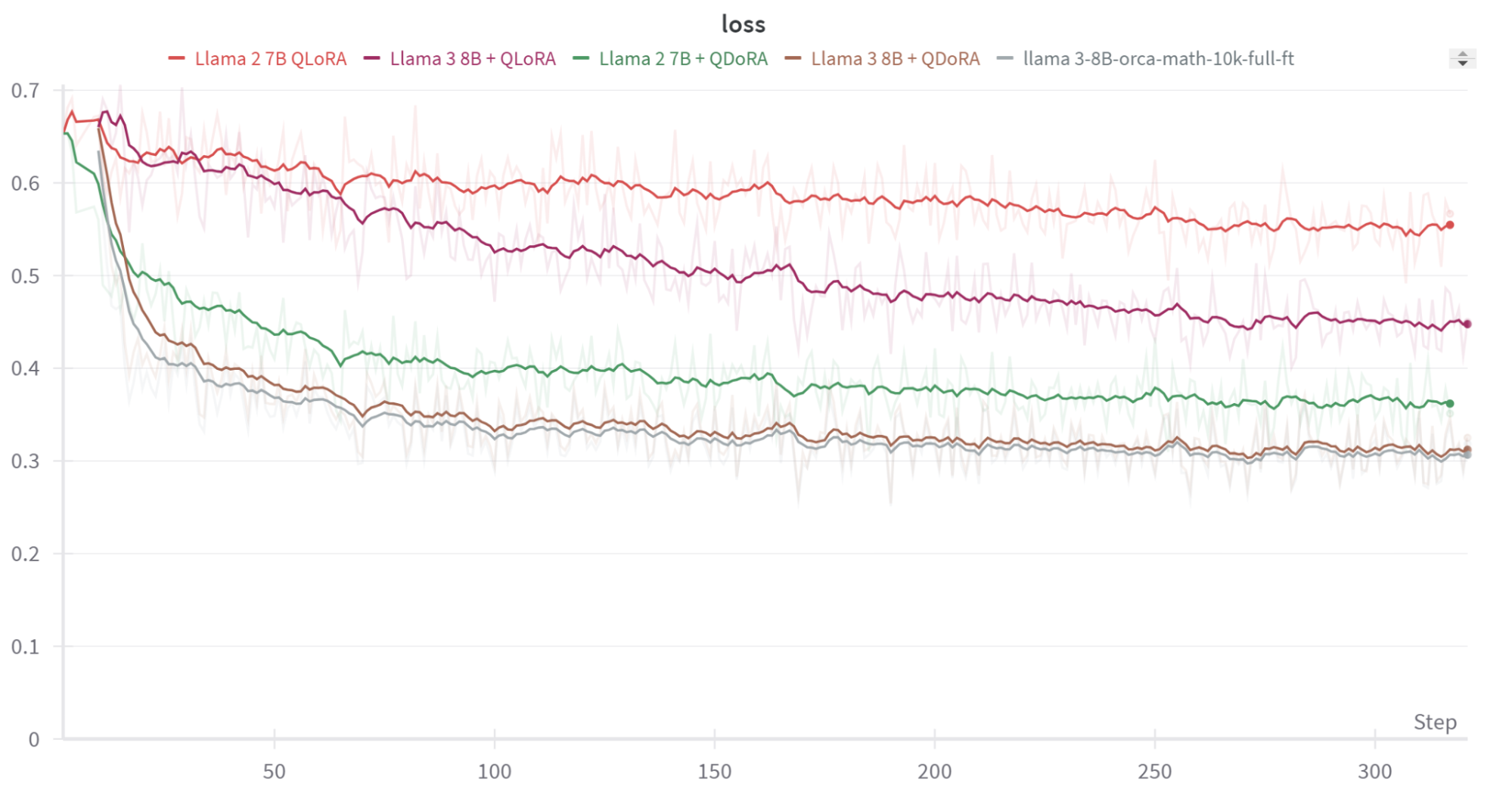
I particularly want to highlight the exceptional work done by Kerem Turgutlu in kicking off and leading this project. Kerem was one of my masters students at the University of San Francisco years ago, and he really stood out with his creativity, work ethic, and intellect. I was very confident he was going to achieve great things – and I very much hoped that we could work together one day. With Answer.AI, I hoped that we had created just the kind of environment that Kerem, and others like him, could reach their full potential. It looks like we may have done just that!
Launching 2 new scalable training methods
*If you’re not familiar with FSDP and LoRA already, please first read our article https://www.answer.ai/posts/2024-03-06-fsdp-qlora.html to learn about the fundamentals on top of which today’s work is built.
Today we’re launching two significant quantized parameter efficient training methods with FSDP compatibility, DoRA (Weight-Decomposed Low-Rank Adaptation) and Llama-Pro (Progressive LLaMA with Block Expansion). These methods are available for use now at the FSDP QLoRA github repository - see Code and Models to get started.
Our early results suggest that QDoRA (“Quantized DoRA”) is especially valuable. There are no other libraries offering QDoRA or quantized Llama-Pro training with FSDP support that we know of. You can see the results fine tuning Llama 2 on the Orca-Math dataset below, where the low-memory QDoRA (quantized DoRA) implementation produces better performance than other methods, whilst using much less memory than full fine-tuning:2
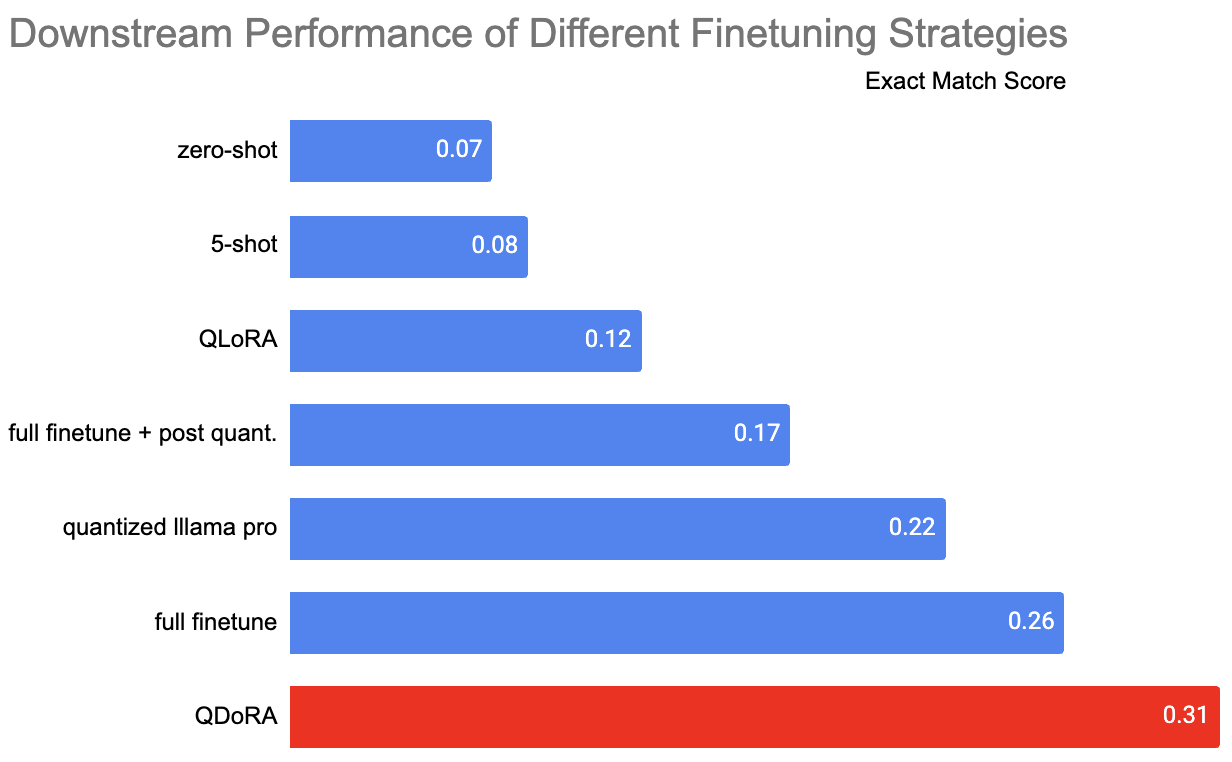
In essence, DoRA combines much of the parameter efficiency of plain QLoRA with the more granular optimization of full finetuning. Using our code, you can use these methods right now for efficient finetuning the most popular open source LLM models including Llama 3 on your own GPUs.
Intrigued? In the sections below, this article will cover the following areas:
- Explanation. Summarizing DoRA and Llama-Pro, to provide a working intuition for how these two optimizations work.
- Deep Dive. Discussing the training setup, benchmarks, and code you can use to run these training optimizations yourself. This benchmark results compare the performance of different training methods, using the Orca-Math dataset
- Hosting. Discussing current options for hosting, a topic which requires special care since not all hosting frameworks support such optimized models
- Future Work. Covering future improvements on production-ready inference and optimized fused kernels for quantized LoRA, DoRA..
- The release of Llama-3. Discussing the potential impact of ever-improving open source base models, and how to leverage our work with them.
LoRA
Inspired by prior work, Hu et al3 hypothesized that most finetuning updates operate at a low intrinsic rank. In other words, updating all the model’s parameters during finetuning is unnecessary, we should be able to finetune models by only updating a subset of parameters. Low-Rank Adaptation (LoRA) implements this idea by freezing the original linear layer weights and instead training a low dimension reparameterization. The output of the frozen layer and trainable LoRA layer are combined to produce the finetuned output.
This setup, especially when combined with quantization such as QLoRA, greatly reduces the memory requirements of finetuning models and popularized Parameter-Efficient Fine-Tuning (PEFT) methods.
While LoRA often matches or nearly matches full finetuning performance, there are cases where it cannot match full finetuning performance, as observed by AnyScale in their in-depth comparison of LoRA and full finetuning.
DoRA
In DoRA: Weight-Decomposed Low-Rank Adaptation, Liu et al4 investigated the capacity gap between LoRA and full finetuning. Inspired by Weight Normalization, they proposed splitting the LoRA layers into two components, one for magnitude and one for direction, and finetuning both. This decomposition allows DoRA to better match the performance of full finetuning while adding a marginal number of parameters to train relative to LoRA.
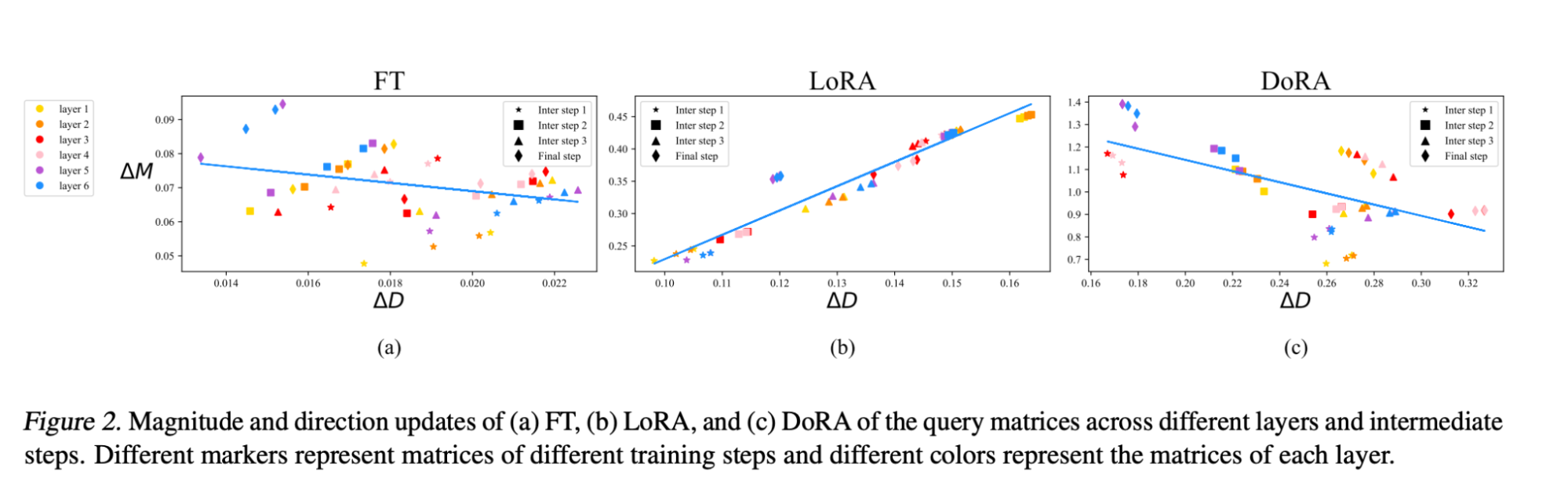
As seen from the weight decomposition analysis in Figure 2. of the DoRA paper, full finetuning (FT) independently optimizes the direction and magnitude of updates to weights. LoRA only updates them in tandem. DoRA is the best of both worlds: it updates them independently, like normal FT, but with the parameter efficiency of LoRA.
Our implementation of FSDP-compatible QDoRA mirrors our QLoRA implementation. Existing pretrained layers are frozen and quantized using bitsandbytes normalized 4-bit float 4 (BnB NF4) or half-quadratic quantization (HQQ) 4-bit formats and are applied to most linear layers, specifically the attention query, key, and value layers and the MLP upscale, gating, and downscale layers. These trainable QDoRA layers represent approximately two percent of the total model parameters.
Llama-Pro
In LLaMA Pro: Progressive LLaMA with Block Expansion, Wu et al5 explores an innovative method for enhancing large language models (LLMs) through a technique called block expansion.
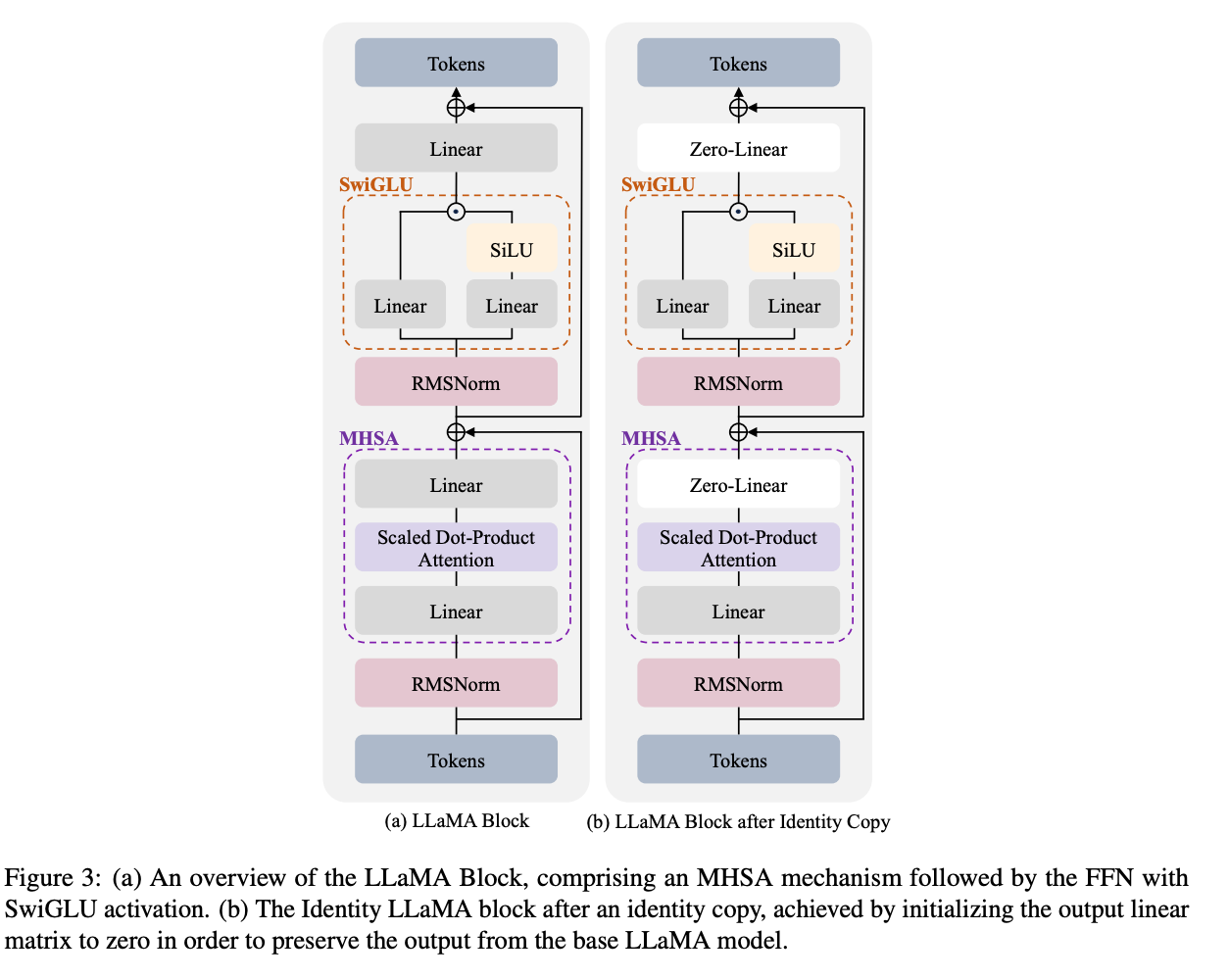
This technique strategically adds Transformer blocks to improve model specialization without sacrificing existing capabilities. Specifically, it interleaves new transformer decoder layers which are initialized as identity functions to maintain model output while integrating new, domain-specific information from tailored datasets such as programming and mathematics. This approach allows the model to extend its depth and refine its specialization areas, providing an advantageous blend of broad general knowledge and sharp, domain-specific expertise without the common downsides of full model retraining or extensive finetuning. The main motivation is to keep the original pretrained weights unchanged and train new layers with skip connections (like resnets) initialized from identity blocks to add new capabilities. So in the perfect scenario, the model should have no regressions from the past training tasks.
In the original implementation of the Llama-Pro, a number of new trainable decoder blocks are interleaved. In our experiments, we follow a similar approach by adding a new decoder block after every 10 layers while quantizing the frozen layers. This is referred to as a 10% expansion rate, which is another hyperparameter that can be tuned depending on the task complexity. These new decoder layers are initialized with the same weights from the preceding layer except for down and output projection layers which are zero-initialized to make the new decoder layer an identity layer.
Training Performance
Training and Evaluation Setup
In most of our experiments we used the Llama-2-7b base model (our work started before the Llama-3 release), the Orca-Math dataset and the following hyperparameters:
| Parameter | Value |
|---|---|
| Epoch | 1 |
| Precision | bf16 |
| Batch Size | 32 |
| Optimizer | AdamW |
| Learning Rate | 1e-5 |
| Learning Rate Schedule | Constant |
| Weight Decay | 0.1 |
| Context Length | 2048 |
| LoRA Rank | 64 |
| LoRA Target Modules | k_proj, q_proj, v_proj, up_proj, down_proj, gate_proj |
| Llama-Pro Expansion Rate | 0.1 |
The dataset contains ~200K grade school math word problems. All the answers in this dataset are generated using GPT4-Turbo. You may refer to Orca-Math: Unlocking the potential of SLMs in Grade School Math for details about the dataset construction. Math is a good testbed for general reasoning skills and it is easier to evaluate compared to more open-ended tasks such as chatbots.
We extract the ground truth labels of the Orca-Math dataset using regex, which identifies the last occurrence of digits that may include leading currency symbols, decimal points, and ratios. We use the exact match score as the evaluation metric. The same set of experiments is conducted with small and large training sample sizes, 10k and 100k respectively. 500 samples are held out for evaluation. In addition to quantization-aware trained models, we also evaluated zero-shot, few-shot, and full finetuning with post-quantization, where all parameters of the model are trained and later quantized with BnB NF4.
Results
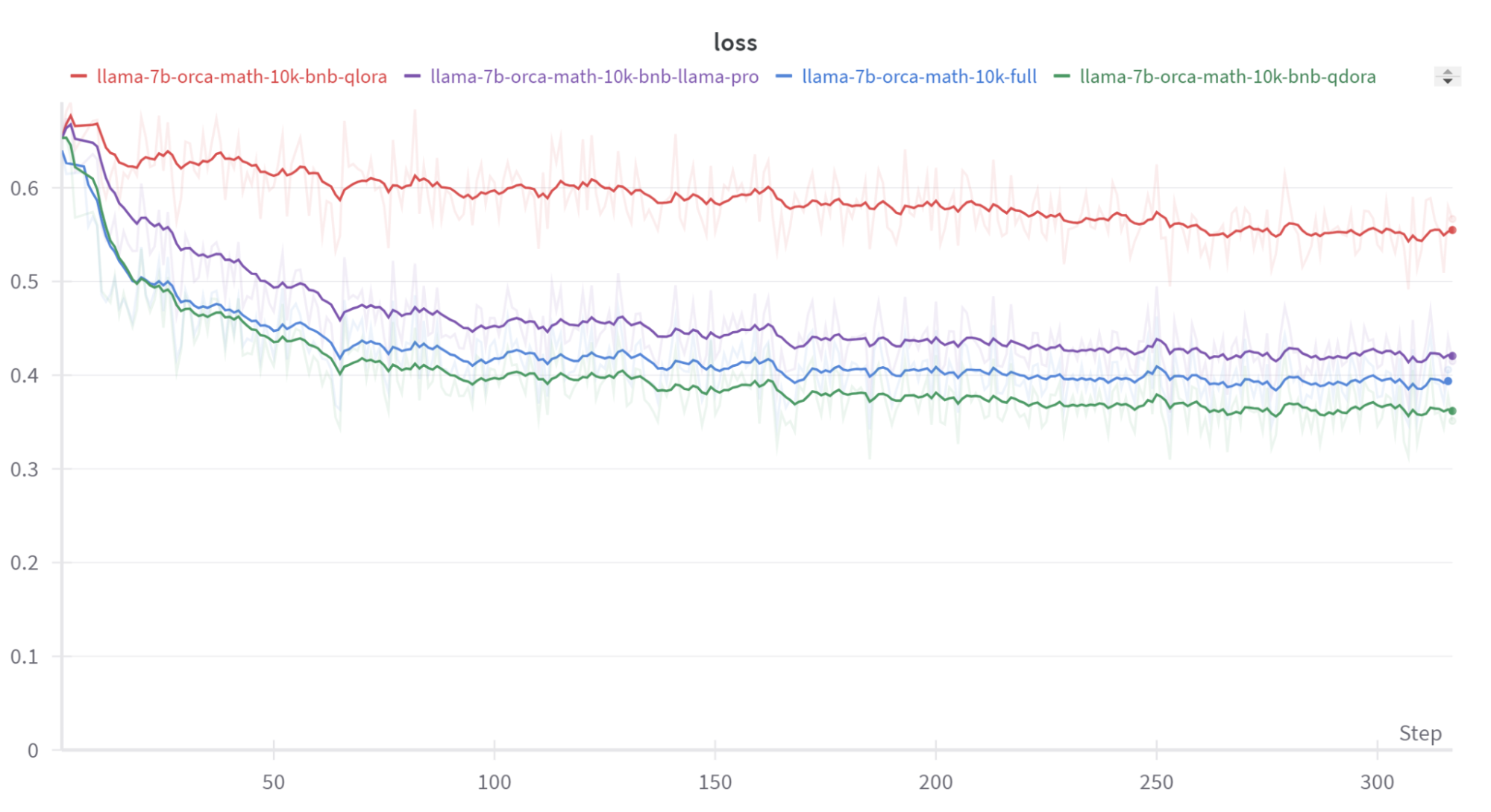
| Model | Method | Train sample size | Eval sample size | Exact match score |
|---|---|---|---|---|
| llama-2-7b | zero-shot | - | 500 | 0.068 |
| llama-2-7b | 5-shot | - | 500 | 0.08 |
| llama-2-7b | full finetune | 10k | 500 | 0.182 |
| llama-2-7b | full finetune + post quant. | 10k | 500 | 0.14 |
| llama-2-7b | QLoRA | 10k | 500 | 0.098 |
| llama-2-7b | QDoRA | 10k | 500 | 0.176 |
| llama-2-7b | quantized llama pro | 10k | 500 | 0.134 |
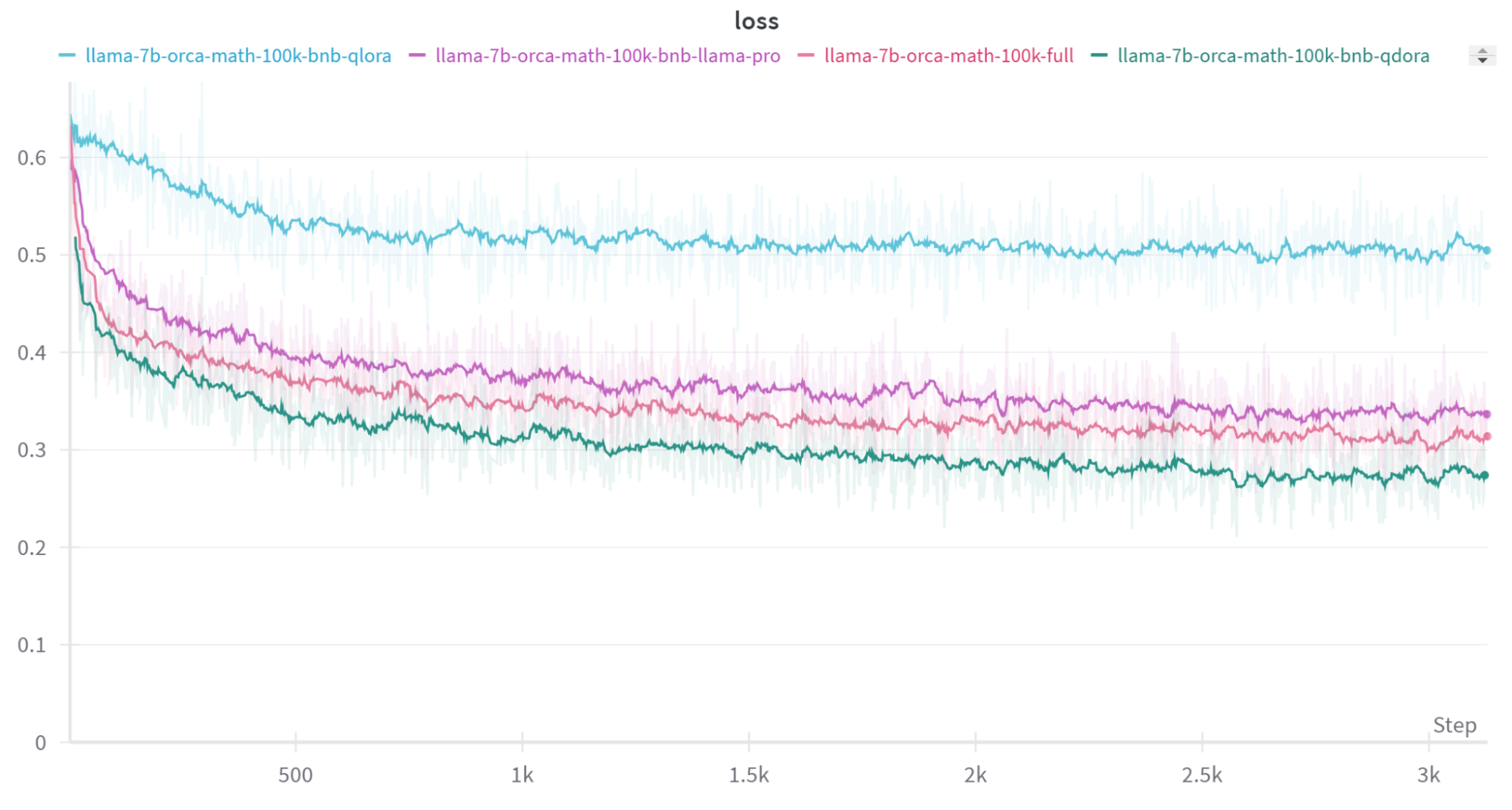
| Model | Method | Train sample size | Eval sample size | Exact match score |
|---|---|---|---|---|
| llama-2-7b | zero-shot | - | 500 | 0.068 |
| llama-2-7b | 5-shot | - | 500 | 0.08 |
| llama-2-7b | full finetune | 100k | 500 | 0.26 |
| llama-2-7b | full finetune + post quant. | 100k | 500 | 0.168 |
| llama-2-7b | QLoRA | 100k | 500 | 0.118 |
| llama-2-7b | QDoRA | 100k | 500 | 0.312 |
| llama-2-7b | quantized llama pro | 100k | 500 | 0.134 |
The key insight from this preliminary study is QDoRA’s edge as a top choice among other quantized, parameter-efficient methods. In our experiments to date, it matches or exceeds the performance of full finetuning, but requires far less memory. (We expect extensive hyperparameter optimization might ultimately push full finetuning to yield the best results, but we have not observed this in our tests.)
While post-quantization significantly degrades performance, it’s worth mentioning that we used BnB NF4 for post-quantization—a weight-only quantization method. Using activation-aware quantization methods like AWQ or GPTQ should improve results, though these methods can’t be used with quantization-aware finetuning and may be susceptible to data biases and shifts. Additionally, the advanced quantization-aware finetuning techniques introduced here are set to revolutionize training for the largest open-source models using FSDP. They promise to cut GPU server costs dramatically while still closely approximating the performance of full finetuning.
Code and Models
To train your own quantization aware fine-tuned models or to reproduce our results you can take a look at the different training options available here - which is from the original FSDP-QLoRA github repo. You can also access all the trained models from our Hugging Face collection.
To train with QDoRA using the same 10k Orca-Math samples:
# Assuming 4 GPUs, if different adjust `gradient_accumulation_steps` to make bs=32.
python fsdp_qlora/train.py \
--train_type bnb_dora \
--model_name meta-llama/Llama-2-7b-hf \
--dataset orca_math \
--dataset_samples 10000 \
--batch_size 4 \
--context_length 2048 \
--gradient_accumulation_steps 2 \
--sharding_strategy full_shard \
--use_gradient_checkpointing true \
--reentrant_checkpointing true \
--use_cpu_offload false \
--use_activation_cpu_offload false \
--log_to wandb \
--project_name "fsdp-quantized-ft-exps" \
--save_model true \
--output_dir models/llama-7b-orca-math-10k-bnb-QDoRABefore Llama-Pro training you need to prepare the expanded version of the model weights to be used during model initialization:
# Adds a new block after every 10 blocks and saves the weights to directory.
python fsdp_qlora/scripts/block_expansion.py \
--model_name meta-llama/Llama-2-7b-hf \
--output_dir /path/to/llama_pro_weights_directory \
--expansion_rate 0.1To train with Llama-Pro:
# Assuming 4 GPUs, if different adjust `gradient_accumulation_steps` to make bs=32.
python fsdp_qlora/train.py \
--train_type bnb_llama_pro \
--llama_pro_path /path/to/llama_pro_weights_directory \
--model_name meta-llama/Llama-2-7b-hf \
--dataset orca_math \
--dataset_samples 10000 \
--batch_size 4 \
--context_length 2048 \
--gradient_accumulation_steps 2 \
--sharding_strategy full_shard \
--use_gradient_checkpointing true \
--reentrant_checkpointing true \
--use_cpu_offload false \
--use_activation_cpu_offload false \
--log_to wandb \
--project_name "fsdp-quantized-ft-exps" \
--save_model true \
--output_dir models/llama-7b-orca-math-10k-bnb-qdoraIn the above examples, you can replace the training type with hqq_dora and hqq_llama_pro to use HQQ 4-bit quantization instead of BnB.
To evaluate the trained models on Orca-Math dataset you can refer to our standalone evaluation python script and evaluation bash script. This evaluation script uses HF’s model.generate() method to evaluate the exact match score between the ground truth answers and the generated text. Using this method on very large datasets is not recommended as it is neither optimized nor suitable for production deployment.
Next, we will take a look at how we can overcome the slow inference problem and potentially make inference much more efficient.
Inference
As we’ve discussed, the QDoRA optimizations allow much faster training. However, they also require some corresponding changes in the inference framework, in order to be able to serve the modified models efficiently.
We looked at vLLM. vLLM is a robust, production-ready framework designed for serving LLM endpoints, offering high throughput and good latency. You can learn more about it in an article on Better Programming which compares and contrasts different frameworks for deploying LLMs. vLLM already supports various quantization methods such as AWQ, GPTQ, SqueezeLLM, and Marlin. Unfortunately, the main branch of vLLM does not currently support weight-only quantization libraries like the ones which we use, BnB and HQQ.
As an initial effort to serve quantization-aware finetuned models, we added BnB and assessed the post-quantization and QDoRA inference performance. Although this implementation is still inefficient and not thoroughly optimized, it performs better than the vanilla HF generate(). Our experimental implementation only works in eager mode and does not work with the CUDA graphs mode in vLLM. Using vLLM’s eager mode, a performance improvement of 1.5-2x can be achieved. This article from Fireworks.ai explains the benefits of using CUDA graphs in the context of decoder-only LLM inference. To enable CUDA graph mode, modifications related to CUDA streams might be necessary, as discussed in this PR. Also, our QDoRA layer is not implemented as a fused kernel, meaning that sequential and separate CUDA kernel launches are required to dequantize, to merge the pretrained weights and LoRA weights, and to compute the final matrix multiplication - we will talk more about potential optimizations in the Future Work section. You can explore our experimental vLLM branch for more details and how the BnB quantization method is integrated into vLLM.
We evaluated throughput and latency of the following models: full finetuned (FFT) post quantized (BnB NF4), QDoRA with separate quantized and LoRA weights, QDoRA with merged weights, and a GPTQ-Marlin post-quantized version of the QDoRA merged model. GPTQ-Marlin FP16x4bit matmul kernel offers the best speedup compared to other methods according to their benchmark results. Note that the QDoRA model with merged weights doesn’t save any memory as the quantized weights are dequantized and merged with LoRA layers. So it is effectively the same as serving a non-quantized model. During GPTQ-Marlin quantization, after merging the QDoRA weights we quantized the model using 3000 samples from the same Orca-Math dataset used during training. We adapted the code from here.
{kind=link}
In our experiments, we also tested tensor parallelism by using multiple GPUs, in which the matrix multiplications are parallelized with either row-parallelism or column parallelism in different layers of the model. Our multi-GPU machine with 4xA5000 is rented from RunPod, which does not have an optimal topology, so the multi-GPU results could be further improved with better interconnect configurations, such as NVLinks. During inference benchmarks, 50 hold-out samples from the validation set were used to compute the exact match score. Variable results were observed, which can be attributed to the tensor-parallelism algorithm.
| Model | Compilation Mode | Model Compr. Rate | TP | Throughput (req/min) | Throughput (tok/sec) | Latency (tok/sec) | Exact match score |
|---|---|---|---|---|---|---|---|
| FFT + Post quant. | Eager | 4X | 1 | 41 | 231 | 15.6 | 0.16 |
| FFT + Post quant. | Eager | 4X | 2 | 65 | 389 | 27.5 | 0.2 |
| FFT + Post quant. | Eager | 4X | 4 | 74 | 381 | 28.1 | 0.2 |
| QDoRA BNB | Eager | 4X | 1 | 15 | 76 | 5.4 | 0.24 |
| QDoRA BNB | Eager | 4X | 2 | 27.5 | 152 | 9.9 | 0.22 |
| QDoRA BNB | Eager | 4X | 4 | 50 | 271 | 18.3 | 0.24 |
| QDoRA (merged) | CUDA Graphs | 1X | 1 | 104 | 546 | 46 | 0.42 |
| QDoRA (merged) | CUDA Graphs | 1X | 2 | 142 | 835 | 67 | 0.36 |
| QDoRA (merged) | CUDA Graphs | 1X | 4 | 172 | 1003 | 76 | 0.38 |
| QDoRA (merged) + GPTQ Marlin | CUDA Graphs | 4X | 1 | 194 | 1122 | 130 | 0.38 |
| QDoRA (merged) + GPTQ Marlin | CUDA Graphs | 4X | 2 | 200 | 1008 | 79 | 0.34 |
Experiments are conducted on the same 4xA5000 machine using the pretrained llama-2 models with different training methods. We leverage the existing vLLM code or our own vLLM BnB integrations where applicable. TP: number of GPUs used for tensor parallelism. Throughput: requests / minute and tokens / minute. Latency: tokens / second, computed by sending a single request with 5 input tokens and forcing 1024 output tokens during generation. Exact match score: 50 held-out sample exact match score.
To prepare the vLLM compatible weight files from the pretrained Orca-Math models you can refer to our standalone python script and bash script.
Even though our custom implementation has much better performance compared to vanilla Hugging Face Transformers, it is still not close to optimized vLLM methods. Full finetuned and post quantized model is nearly 5x slower compared to GPTQ Marlin, and QDoRA is 15x slower. We can also see that GPTQ Marlin is both faster and 4x more memory efficient than the un-quantized vLLM model (QDoRA merged). This inspires future work to improve the weight-only quantization methods with faster kernels, and to implement a fused QDoRA layer.
That being said, GPTQ-Marlin post-quantization following the merging of DoRA weights could serve as a temporary solution if deploying merged weights directly is not feasible. We are actively collaborating with the authors of open-source quantization libraries to enhance the efficiency of HQQ-LoRA/DoRA integrations.
Future Work
We’ve seen in the case of work such as flash attention that IO-aware fused kernels can provide substantial performance improvements. We’re collaborating with others in the community to build out fused kernels for quantization and LoRA/DoRa adapters to make the use of these finetuning approaches more efficient in both training and inference. We will also continue to work on enabling CUDA Graphs for BnB and HQQ in vLLM, as well as Marlin compatible HQQ-DoRA finetuning. Feel free to reach out if you’re interested in contributing to this effort.
Enter Llama 3
Last Thursday, Meta AI released two potent new base models for finetuning with the release of Llama 3 8B and 70B, with an even larger 400B+ parameters model on the way. Both of the released models have been trained on >15 trillion tokens, and exhibit extremely strong performance on both formal benchmarks and the LMSYS Chatbot Arena.
As Jeremy discussed in the introduction of this post, we believe that powerful open source models finetuned with the right tools, will continuously improve and yield better performance than even the strongest proprietary models. Llama 3 represents a gigantic step in this direction, and indeed the community is more than eager to put this theory to the test: in the space of just a single week-end, thousands of Llama 3 finetunes have already been uploaded to the HuggingFace model hub.
We are eager for our work to make these advances even more accessible. The work we have done on FSDP-QLoRA and QDoRA is immediately applicable to Llama-3: the only change necessary to use FSDP-QDoRA with Llama3 is updating the --model-name parameter in the scripts above to meta-llama/Meta-Llama-3-{8B|70B}-{|Instruct}.
# Assuming 4 GPUs, if different adjust `gradient_accumulation_steps` to make bs=32.
python fsdp_qlora/train.py \
--train_type bnb_dora \
--model_name meta-llama/Meta-Llama-3-8B \
--dataset orca_math \
--dataset_samples 10000 \
--batch_size 4 \
--context_length 2048 \
--gradient_accumulation_steps 2 \
--sharding_strategy full_shard \
--use_gradient_checkpointing true \
--reentrant_checkpointing true \
--use_cpu_offload false \
--use_activation_cpu_offload false \
--log_to wandb \
--project_name "fsdp-quantized-ft-exps" \
--save_model true \
--output_dir models/Llama-3-8b-orca-math-10k-bnb-QDoRAOur training code allows for quick, efficient and powerful finetuning of the new models. As a result, it is now within reach of the community to match task-specific GPT-4 performance at home with a dozen lines of code. We’re very excited to see what exciting continuously pre-trained models will appear over the next few weeks!
General timeline

Credits
Special thanks to Benjamin Clavié for helping with the vLLM BnB integration, to Johno Whitaker for running the initial experiments on Llama-3, to Alexis Gallagher for editorial comments and suggestions, and to Austin Huang, Benjamin Warner, Griffin Adams, Eric Ries and Jeremy Howard for reviewing and improving the initial version of this blog post.
Footnotes
In this post “train” means using gradient descent to modify weights in a model. That could be used for training random weights from scratch (“pre-training”) or starting from pre-trained weights (“finetuning” or “continued pre-training”). In practice, there’s very rarely any need for starting with random weights, so nearly everyone reading this will be interested in finetuning, and that’s all that we’ve actually tested QDoRA with. But the term “finetuning” comes with a lot of now-obsolete assumed limitations, and “continuous pre-training” is a bit of a mouthful.↩︎
Because Llama 3 has only just been released, we haven’t had time to do extensive experiments yet. We’d expect that with better hyperparameter optimization we’ll see full finetuning and QDoRA at around the same accuracy.↩︎
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, LoRA: Low-Rank Adaptation of Large Language Models (2021)↩︎
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, Min-Hung Chen, DoRA: Weight-Decomposed Low-Rank Adaptation (2024)↩︎
Chengyue Wu and Yukang Gan and Yixiao Ge and Zeyu Lu and Jiahao Wang and Ye Feng and Ping Luo and Ying Shan, LLaMA Pro: Progressive LLaMA with Block Expansion (2024)↩︎